Nudgebee est une plateforme CloudOps open source qui veut réunir SRE, FinOps, Kubernetes Ops, runbooks et assistant IA dans un même cockpit. Mon verdict court : l’idée est solide et certains blocs tournent vraiment, mais le projet reste lourd à installer et pas encore assez lisse pour une équipe qui veut juste brancher un outil et produire des résultats en une heure.
Nudgebee, c’est quoi ?
Nudgebee se présente comme un copilot SRE open source. Le dépôt vise un usage assez ambitieux : surveiller des clusters Kubernetes, scanner des comptes cloud, classer des recommandations, lancer des runbooks, parler à des services de ticketing et exposer une interface Next.js pour piloter tout ça.
Sur le papier, le produit veut éviter la pile classique en mille morceaux : un outil pour les coûts, un autre pour les incidents, un autre pour les runbooks, un autre pour l’IA. Ici, tout est pensé comme une plateforme centralisée.
La structure du dépôt confirme cette ambition. On trouve une app web, un serveur API Go, un serveur de runbooks, des collecteurs cloud et Kubernetes, un serveur LLM, un RAG server, du ticketing, des notifications et même un service ML pour le right-sizing Kubernetes.
| Élément testé | Résultat observé |
|---|---|
| Dépôt | Monorepo Go, TypeScript, Python |
| Prérequis annoncés | Docker, Go 1.26, Node 25, npm 11 |
| Frontend | Installation réussie avec Node 25, lancement Next.js OK |
| Runbook engine | Tests de dry-run exécutés, sortie workflow réelle |
| Stack complète | Bloquée ici car Docker n’était pas disponible |
| Qualité perçue | Ambitieuse, mais encore rugueuse |
Installation de Nudgebee
J’ai cloné le dépôt GitHub dans un dossier temporaire, puis j’ai lu le README et les fichiers de dépendances. Premier point important : Nudgebee n’est pas un petit binaire à lancer. C’est une vraie plateforme distribuée.
La voie officielle demande Docker Compose pour PostgreSQL, Redis, RabbitMQ, Qdrant et Temporal, puis Go 1.26 pour les backends et Node 25 pour l’app web.
Les commandes de base documentées ressemblent à ça :
git clone https://github.com/nudgebee/nudgebee.git
cd nudgebee
docker compose up -d
cp api-server/services/.env.example api-server/services/.env
cp app/.env.example app/.env
cd app
npm install --legacy-peer-deps
npm run dev
Dans mon environnement de test, Docker n’était pas installé. Je n’ai donc pas pu lancer la plateforme complète avec Postgres, RabbitMQ, Qdrant et Temporal. En revanche, j’ai installé les runtimes manquants côté source : Go 1.26.1 et Node 25.9.0 avec npm 11.12.1.
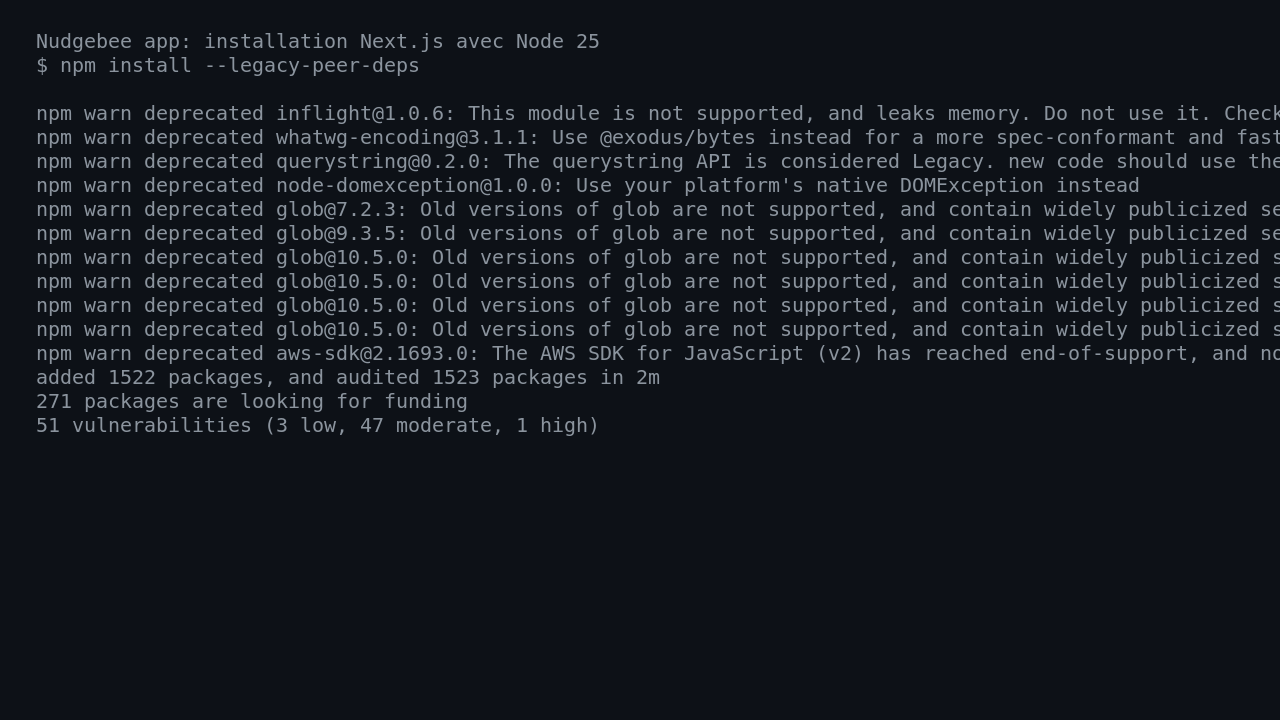
L’installation de l’app Next.js a réussi avec Node 25 : 1522 paquets installés, 51 vulnérabilités npm signalées, dont une haute. Ce n’est pas rare sur une grosse app frontend, mais c’est le genre de dette que je regarde de près avant de mettre un outil d’exploitation en prod.
Nudgebee à l’usage
Je voulais éviter le faux test où l’on dit seulement : le serveur démarre. J’ai donc testé deux chemins concrets.
Le premier chemin : lancer l’app web. Après configuration de l’environnement local, le serveur Next.js a démarré sur le port 3000. La page HTTP répondait bien, les styles et le shell de l’interface étaient servis. Le backend complet n’étant pas disponible, je n’ai pas pu valider un flux complet avec intégration cloud ou cluster Kubernetes réel.
Le deuxième chemin : faire tourner le moteur de runbooks côté Go, qui est un des morceaux les plus intéressants du produit. J’ai exécuté des tests ciblés sur runbook-server/internal/workflow, notamment le dry-run executor. Là, Nudgebee produit quelque chose de concret : il démarre un workflow de test, injecte le mode dry-run, exécute une tâche core.print, marque la tâche comme terminée et retourne une sortie.
La commande utilisée :
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
export OPENAI_API_BASE=http://172.17.0.1:8790/v1
export OPENROUTER_BASE_URL=http://172.17.0.1:8790/v1
export OPENROUTER_API_KEY=sk-proxy
go test ./internal/workflow -run 'TestExecutorDryRunTestSuite' -v
Sortie significative observée :
Starting workflow workflowId test-dryrun-wf tenantID test-tenant accountID test-account
DryRun: Executing task with dry-run flag taskID task1 taskType core.print
Task completed taskID task1 result executed
Workflow completed successfully
Workflow execution completed workflowId test-dryrun-wf result map[task1:executed]
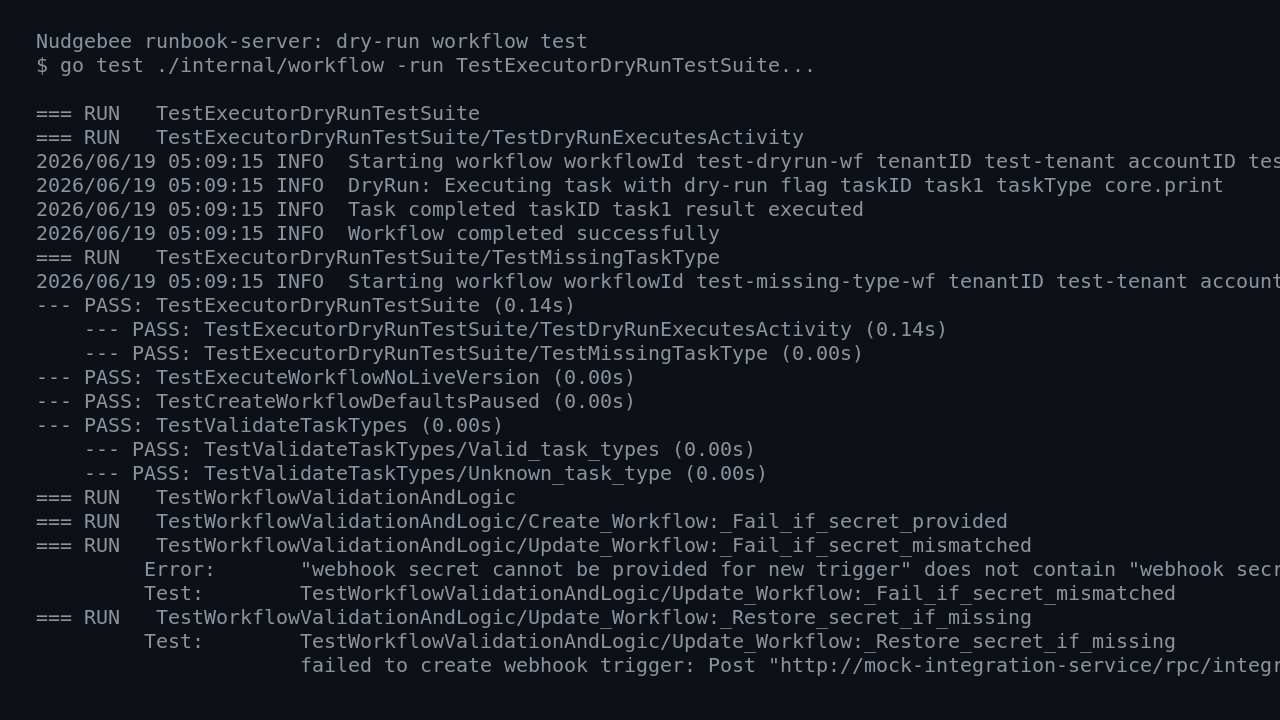
J’ai aussi lancé une série de tests de parsing, validation DAG, templating et routage switch. Beaucoup passent, ce qui montre que le coeur runbook n’est pas juste une façade. Mais j’ai aussi vu des échecs nets : un filtre de template realpath annoncé par le test n’est pas enregistré, et une logique de secret webhook échoue en tentant de joindre mock-integration-service via DNS.
Ce que j’aime dans Nudgebee
Ce que j’aime le plus, c’est le cadrage produit. Nudgebee ne se contente pas de dire IA pour vendre un dashboard. Le dépôt contient des briques opérationnelles classiques : workflows, tenants, comptes, intégrations, audit, tickets, notifications, scan orchestrator, collecteurs et Temporal.
J’aime aussi l’idée du runbook YAML versionné. Pour une équipe DevOps, c’est plus utile qu’un simple chatbot. Un runbook doit être relançable, auditable, validé et relié à des déclencheurs. Nudgebee part dans cette direction.
Autre point positif : le README est assez honnête sur la complexité. Il explique les services minimaux requis, les dépendances par composant et les limites du dry-run. C’est précieux, car un dry-run qui appelle quand même des systèmes externes peut surprendre en production.
Les limites de Nudgebee
La première limite est l’installation. Docker, Go 1.26, Node 25, npm 11, Temporal, RabbitMQ, Redis, Qdrant, Postgres : c’est une stack sérieuse. Pour une grosse équipe plateforme, ça se défend. Pour un freelance ou une petite PME, c’est beaucoup.
La deuxième limite est la maturité perçue. Les tests que j’ai lancés ne sont pas tous verts. Un filtre de templating manquant et un test qui part résoudre un service mock en DNS externe, ce n’est pas dramatique pour un projet en mouvement, mais ça signale que certaines zones ne sont pas encore polies.
La troisième limite est que la valeur réelle demande des intégrations. Sans cluster Kubernetes, sans compte cloud, sans Slack ou Teams, sans backend complet, l’interface reste assez vide. Nudgebee n’est pas un outil que l’on juge uniquement sur son écran d’accueil.
Est-ce que Nudgebee marche vraiment ?
Oui, partiellement, dans ce que j’ai pu exécuter. Le frontend Next.js s’installe et se lance. Le moteur de runbooks exécute un dry-run réel et produit une sortie de workflow. Les validateurs de parsing, de DAG et de templating couvrent des cas concrets.
Non, je ne peux pas dire que la plateforme complète est validée de bout en bout dans ce test. L’absence de Docker a bloqué le lancement officiel avec les bases, files de messages et services complets. Je préfère le dire clairement plutôt que de vendre une validation que je n’ai pas faite.
Pour un lecteur qui veut tester Nudgebee, je conseille de le faire sur une machine avec Docker Compose fonctionnel et assez de RAM. Ensuite, le vrai test à mener est simple : connecter un cluster Kubernetes de lab, importer quelques ressources volontairement imparfaites, puis regarder si les recommandations et runbooks aident vraiment à agir.
Faut-il adopter Nudgebee ?
Mon verdict : à essayer si vous avez une équipe plateforme, une culture SRE et l’envie d’expérimenter un outil open source ambitieux. À adopter en production seulement après un vrai pilote, avec revue sécurité, revue des dépendances npm, secrets bien configurés et tests sur vos propres intégrations.
Pour un freelance DevOps, je le vois plutôt comme une source d’inspiration et un labo. Le runbook engine est intéressant. La plateforme complète est encore trop lourde pour remplacer rapidement une chaîne plus simple basée sur Prometheus, Grafana, scripts GitOps et quelques automatisations ciblées.
Pour une startup infra ou une équipe qui souffre de trop d’outils fragmentés, Nudgebee mérite une place dans la short-list. Pas parce que tout est magique, mais parce que le projet attaque un vrai problème.
FAQ
Nudgebee est-il gratuit ?
Le dépôt GitHub est open source sous licence Apache 2.0. Il faut tout de même compter le coût d’exploitation de la stack : bases, queue, Temporal, stockage, compute et temps d’intégration.
Nudgebee remplace-t-il Grafana ou Prometheus ?
Pas directement. Nudgebee se place plutôt au-dessus des signaux, pour corréler, recommander et automatiser. Dans une vraie stack, il pourrait compléter l’observabilité existante plutôt que la remplacer.
Nudgebee est-il prêt pour la production ?
Je serais prudent. Les briques sont prometteuses, mais mon test a vu des rugosités et je n’ai pas validé la stack complète. Je le classerais comme outil à piloter sérieusement avant adoption.