KubeShark is a Kubernetes skill for Claude Code and Codex, designed to prevent YAML manifests from being generated purely by guesswork. After a real test on a deliberately fragile Deployment, my verdict is straightforward: useful as a generation and review guardrail, but not enough to replace serious DevOps validation.
What is KubeShark?
KubeShark, from the LukasNiessen/kubernetes-skill repository, is not a Kubernetes binary or a cluster scanner. It’s a package of guidelines, references, and patterns designed to guide a code agent when generating or reviewing Kubernetes configs.
The idea is concrete: instead of asking an LLM to spit out a Deployment from scratch, you enforce a 7-step workflow. It must capture context, diagnose likely failures, load relevant references, propose guardrails, generate manifests, plan for validation, and provide a rollback strategy.
The failure modes covered will resonate with anyone who has seen dangerous YAML in production: overly permissive defaults, missing resource limits, network exposure, overly broad RBAC, fragile rollout, API drift.
| Element tested | Observed result |
|---|---|
| Project type | Claude Code and Codex skill, Markdown files |
| Installation tested | Per-project installation, Codex-style, via AGENTS.md |
| Use case | Review and correction of a fragile Kubernetes Deployment |
| Model used | openai/gpt-4o-mini via OpenAI-compatible proxy |
| Validation | kubeconform Kubernetes 1.30 and custom static checks |
| Short verdict | Worth trying, especially to constrain an agent, not for standalone validation |
Installing KubeShark
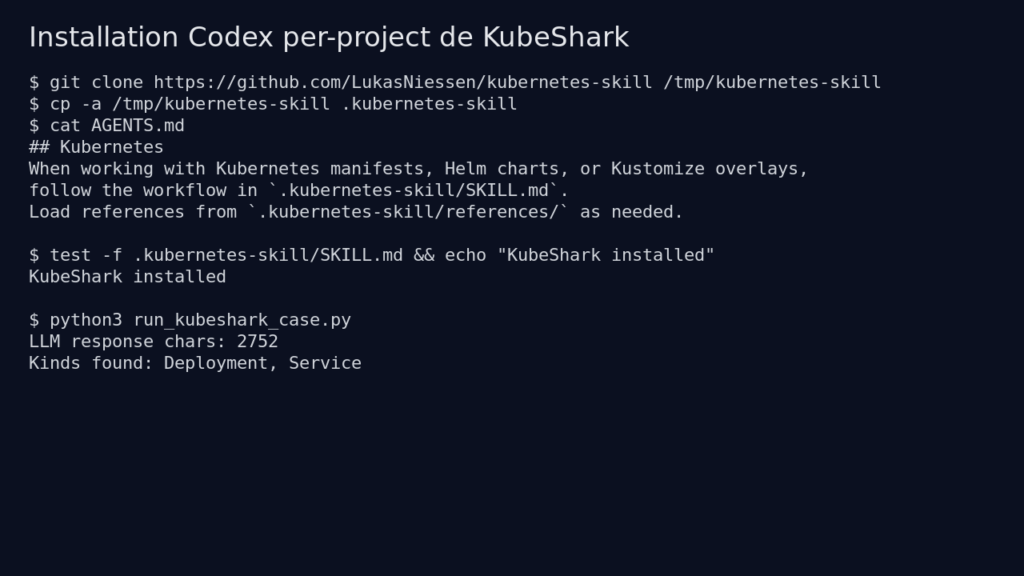
I cloned the repository into /tmp, then read through the README, SKILL.md, the references, and the installation docs. The project is very simple: no compilation, no server, no mandatory runtime dependency for the skill itself.
For Codex mode, the official installation involves placing the repository in your project and referencing it in AGENTS.md:
git clone https://github.com/LukasNiessen/kubernetes-skill.git .kubernetes-skill
cat > AGENTS.md <<'EOF'
## Kubernetes
When working with Kubernetes manifests, Helm charts, or Kustomize overlays,
follow the workflow in `.kubernetes-skill/SKILL.md`.
Load references from `.kubernetes-skill/references/` as needed.
EOF
In my test environment, neither Claude Code nor Codex CLI was available. So I reproduced the actual mechanism Codex expects: a project with .kubernetes-skill, an AGENTS.md, then an OpenAI-compatible LLM call that loads SKILL.md and the relevant references. This is not a simple summary of the README: the skill genuinely drove the response and the resulting Kubernetes manifest.
KubeShark in Practice
My test case was deliberately classic and therefore realistic: a payments-api Deployment in default, a single replica, an nginx:latest image, no requests or limits, no probes, no securityContext, a base URL as an environment variable, and a LoadBalancer type Service.
I asked for a correction targeting Kubernetes 1.30, the payments-staging namespace, a Pod Security Admission profile of baseline now with a goal of restricted, exposure behind an internal Ingress with no public LoadBalancer.
First pass: KubeShark correctly identified several important issues. It changed the namespace, replaced the LoadBalancer with a ClusterIP, added a securityContext, probes, and a versioned image. The extracted YAML was valid against the Kubernetes schema using kubeconform.
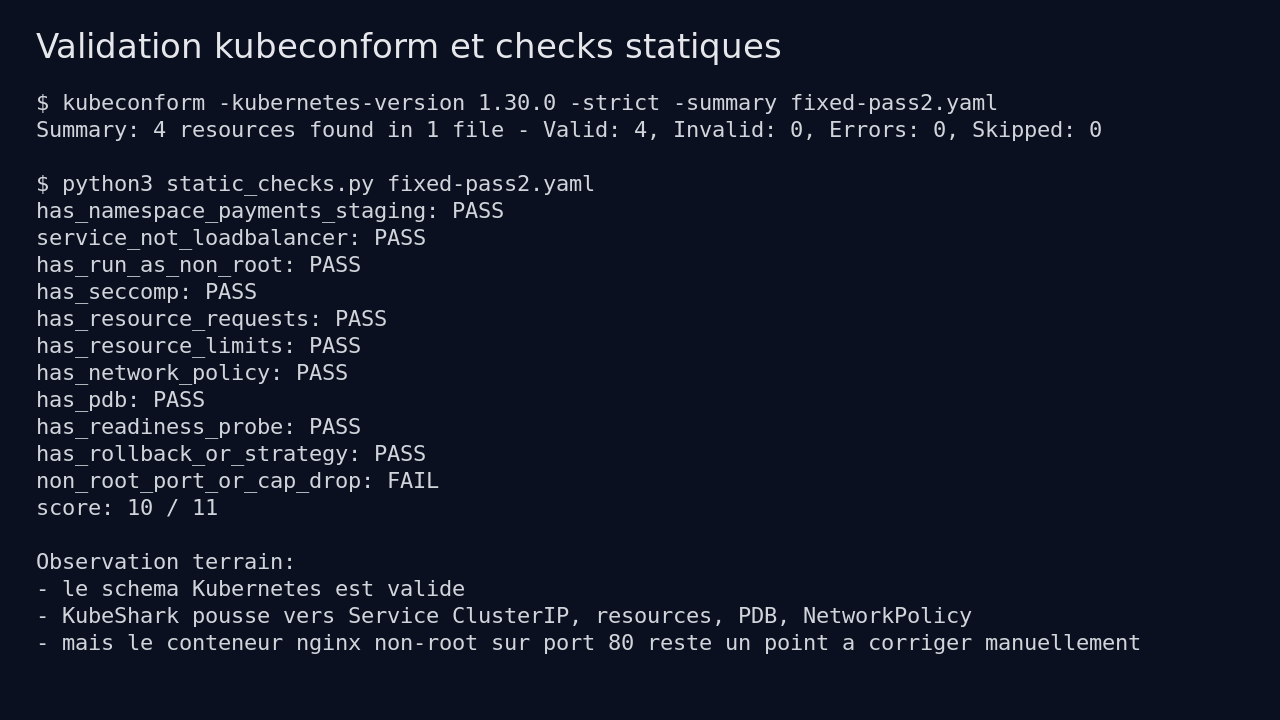
But several elements the skill promises to enforce were still missing: requests, limits, PDB, NetworkPolicy, rollout strategy. My static checks returned only 5 passes out of 10.
I then ran a second pass, feeding the agent the results of those checks. This time, KubeShark produced a more complete manifest: Deployment, Service, PodDisruptionBudget, and NetworkPolicy, with CPU and memory resources, rolling update, correct namespace, and internal service.
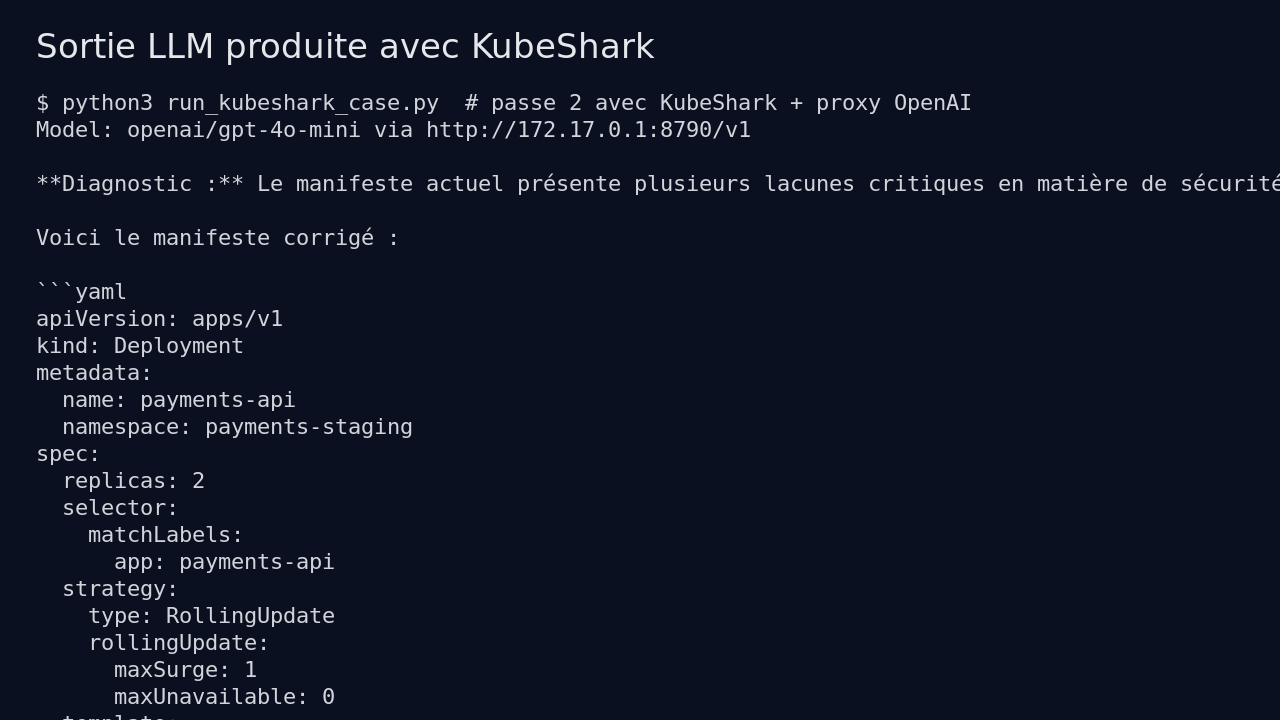
The second-pass manifest cleared kubeconform:
kubeconform -kubernetes-version 1.30.0 -strict -summary fixed-pass2.yaml
Observed result:
Summary: 4 resources found in 1 file - Valid: 4, Invalid: 0, Errors: 0, Skipped: 0
My static checks validated 10 out of 11 points: namespace, non-public service, runAsNonRoot, seccomp, resources, NetworkPolicy, PDB, readiness probe, and rollout strategy.
Does KubeShark Actually Work?
Yes, in the right sense: it keeps the LLM on track. Without being magic, it forces a more structured response than a generic Kubernetes prompt would.
The tool genuinely produced a useful artifact: a multi-resource Kubernetes manifest, schema-valid, with guardrails that were absent from the original. For a security or DevOps freelancer, that’s interesting because the skill turns a vague request into a risk review covering network exposure, resources, pod security, and rollback.
The most convincing part is the structure. The skill doesn’t just say “here’s some YAML.” It pushes toward hypotheses, failure modes, validation commands, and rollback notes. That’s exactly what’s usually missing from LLM responses on Kubernetes.
KubeShark’s Limitations
The main limitation: KubeShark is a skill, meaning a reasoning framework. It doesn’t replace a test cluster, kubectl diff, an admission policy, or a human review.
My test also surfaced an important point. The second pass added runAsUser: 1000, but kept nginx on port 80. On a non-root container, listening on a privileged port can break depending on the image. The Kubernetes schema is valid, but the runtime behavior still needs verification.
Another limitation: the first draft was incomplete. It improved the manifest, but not to the “production-ready” level the skill advertises. A feedback loop with static checks was necessary.
Finally, there’s no autonomous execution. No KubeShark CLI that scans a folder, no JSON report, no direct integration with kubectl. If you want a reliable pipeline, you need to wrap it with kubeconform, kube-score, Kyverno, OPA Gatekeeper, or your own tests.
What I Like About KubeShark
I like the lightweight format. The repository is readable, references are organized by topic, and the main workflow fits in a clear SKILL.md.
I also like the failure-mode approach. It’s far more operational than a vague list of best practices. When talking Kubernetes, “securityContext” alone isn’t enough. You need to think about networking, rollout, resources, APIs, secrets, RBAC, and rollback.
Another plus: the token efficiency effort. References are split up, so an agent can load only what’s relevant. In theory, this prevents drowning the model in the entire Kubernetes documentation.
What I Don’t Like About KubeShark
I’m not a fan of the name “KubeShark” if you’re expecting a tool that observes a cluster. The name almost implies a scanner or network analyzer, while the project is actually a generation and review skill.
I also find the marketing promise a bit overblown. “Eliminate hallucinations” is too ambitious. My test shows it’s more accurate to say “reduces common omissions, especially when paired with validation loops.” That’s already valuable, but it’s a different promise.
One last point: without Claude Code or Codex in the loop, you have to cobble together a test harness. That’s not a problem for the intended audience, but for a general reader, it’s worth understanding that installation mainly activates agent behavior.
Should You Adopt KubeShark?
My verdict: worth trying if you’re already using Claude Code or Codex to write Kubernetes configs. I’d adopt it as a prompt guardrail in an infrastructure repo, especially to avoid bare manifests with no resources, no probes, and no network thinking.
I wouldn’t adopt it as a standalone validation tool. The right approach, in my view: KubeShark to constrain the agent, then automated validation with schema checks, policies, deployment tests, and human review.
For a DevOps team, it’s useful in three cases: generating Helm or YAML drafts, quickly reviewing manifests, and onboarding developers who touch Kubernetes without being experts. For sensitive production workloads, it should remain a first line of defense, not the final word.
FAQ
Does KubeShark install anything in the cluster?
No. KubeShark is a skill for code agents. It guides manifest generation and review, but it doesn’t deploy anything to Kubernetes on its own.
Does KubeShark replace kubeconform or Kyverno?
No. It can suggest better manifests, but you still need to validate with deterministic tools. In my test, kubeconform confirmed the schema, but a runtime detail still needed verification.
Is KubeShark worth it for a DevOps freelancer?
Yes, if you’re already using an AI agent in your infrastructure repos. It helps structure responses and avoid common omissions, but it needs to be integrated into a real control pipeline.