KubeShark est un skill Kubernetes pour Claude Code et Codex, pensé pour éviter les manifests YAML bricolés au feeling. Après un vrai essai sur un Deployment volontairement fragile, mon verdict est simple : utile comme garde-fou de génération et de revue, mais pas suffisant pour remplacer une validation DevOps sérieuse.
KubeShark, c’est quoi ?
KubeShark, dans le dépôt LukasNiessen/kubernetes-skill, n’est pas un binaire Kubernetes ni un scanner de cluster. C’est un paquet de consignes, de références et de patterns pour guider un agent de code quand il génère ou relit du Kubernetes.
L’idée est concrète : au lieu de demander à un LLM de sortir un Deployment au hasard, on lui impose un workflow en 7 étapes. Il doit capturer le contexte, diagnostiquer les pannes probables, charger les références utiles, proposer des garde-fous, générer les manifests, prévoir la validation, puis donner un rollback.
Les modes de panne couverts parlent aux gens qui ont déjà vu du YAML dangereux en prod : defaults trop permissifs, ressources absentes, exposition réseau, RBAC trop large, rollout fragile, dérive d’API.
| Élément testé | Résultat observé |
|---|---|
| Type de projet | Skill Claude Code et Codex, fichiers Markdown |
| Installation testée | Installation par projet, façon Codex, via AGENTS.md |
| Cas d’usage | Revue et correction d’un Deployment Kubernetes fragile |
| Modèle utilisé | openai/gpt-4o-mini via proxy compatible OpenAI |
| Validation | kubeconform Kubernetes 1.30 et checks statiques maison |
| Verdict court | À essayer, surtout pour cadrer un agent, pas pour valider seul |
Installation de KubeShark
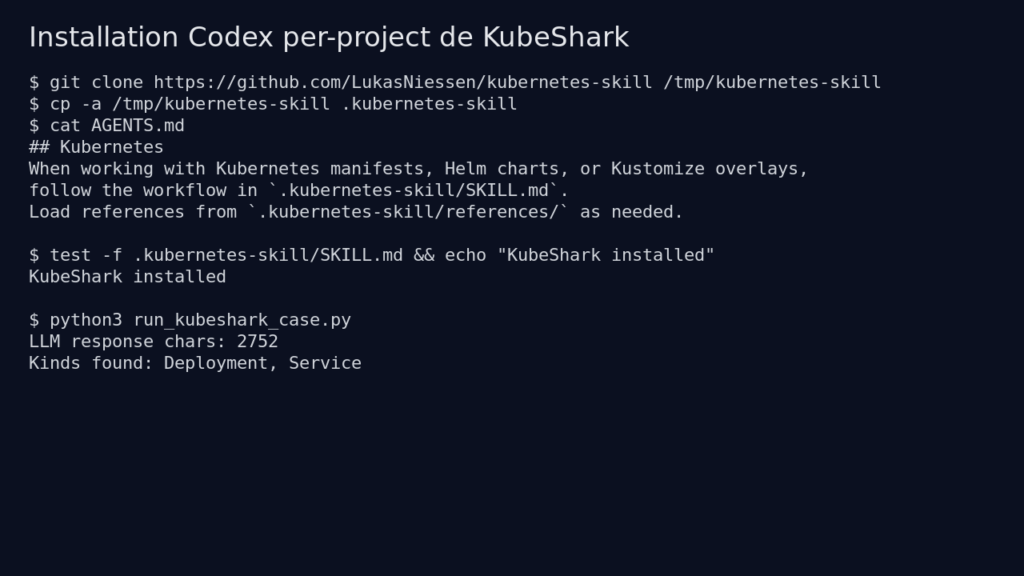
J’ai cloné le dépôt dans /tmp, puis j’ai lu le README, SKILL.md, les références et la documentation d’installation. Le projet est très simple : pas de compilation, pas de serveur, pas de dépendance runtime obligatoire pour le skill lui-même.
Pour le mode Codex, l’installation officielle consiste à placer le dépôt dans le projet, puis à le référencer dans AGENTS.md :
git clone https://github.com/LukasNiessen/kubernetes-skill.git .kubernetes-skill
cat > AGENTS.md <<'EOF'
## Kubernetes
When working with Kubernetes manifests, Helm charts, or Kustomize overlays,
follow the workflow in `.kubernetes-skill/SKILL.md`.
Load references from `.kubernetes-skill/references/` as needed.
EOF
Dans mon environnement de test, ni Claude Code ni Codex CLI n’étaient disponibles. J’ai donc reproduit le mécanisme réel attendu par Codex : un projet avec .kubernetes-skill, un AGENTS.md, puis un appel LLM compatible OpenAI qui charge SKILL.md et les références pertinentes. Ce n’est pas un simple résumé du README : le skill a bien servi à produire une réponse et un manifeste Kubernetes.
KubeShark à l’usage
Mon cas de test était volontairement classique, donc réaliste : un Deployment payments-api dans default, une seule réplique, une image nginx:latest, pas de requests ni limits, pas de probes, pas de securityContext, une URL de base en variable d’environnement et un Service de type LoadBalancer.
J’ai demandé une correction pour Kubernetes 1.30, namespace payments-staging, profil Pod Security Admission baseline aujourd’hui, objectif restricted, exposition derrière un Ingress interne et pas de LoadBalancer public.
Première passe : KubeShark a bien identifié plusieurs problèmes importants. Il a changé le namespace, remplacé le LoadBalancer par un ClusterIP, ajouté un securityContext, des probes et une image versionnée. Le YAML extrait était valide au schéma Kubernetes avec kubeconform.
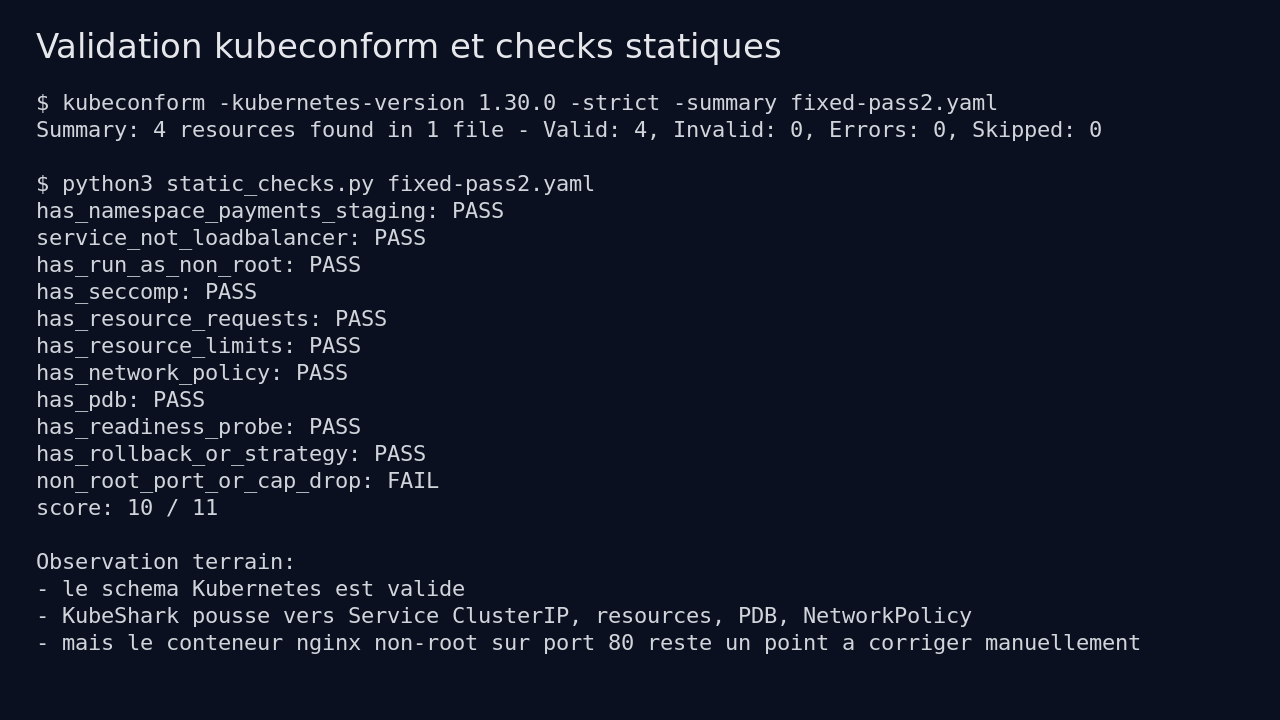
Mais il manquait encore des éléments que le skill promet de pousser : requests, limits, PDB, NetworkPolicy, stratégie de rollout. Mes checks statiques donnaient seulement 5 réussites sur 10.
J’ai donc lancé une deuxième passe en donnant à l’agent le résultat de ces checks. Là, KubeShark a produit un manifeste plus complet : Deployment, Service, PodDisruptionBudget et NetworkPolicy, avec ressources CPU et mémoire, rolling update, namespace correct et service interne.
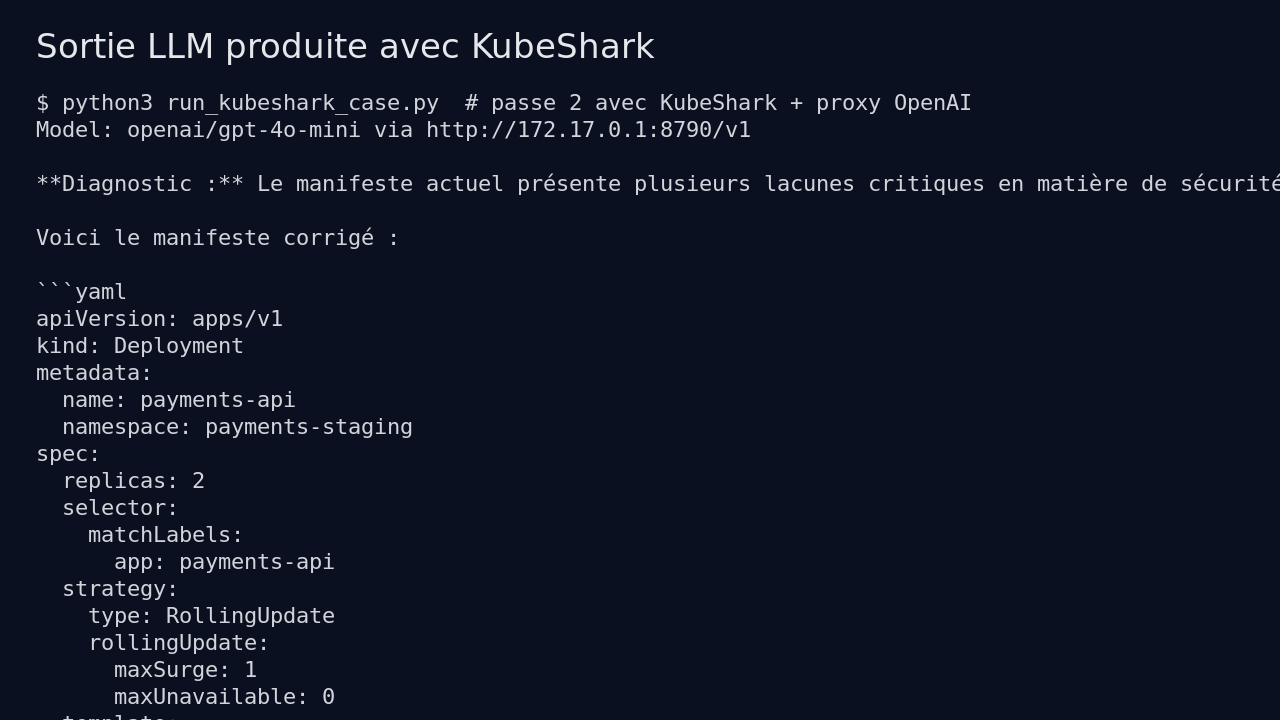
Le manifeste de deuxième passe est passé dans kubeconform :
kubeconform -kubernetes-version 1.30.0 -strict -summary fixed-pass2.yaml
Résultat observé :
Summary: 4 resources found in 1 file - Valid: 4, Invalid: 0, Errors: 0, Skipped: 0
Mes checks statiques ont validé 10 points sur 11 : namespace, service non public, runAsNonRoot, seccomp, ressources, NetworkPolicy, PDB, readiness probe et stratégie de rollout.
Est-ce que KubeShark marche vraiment ?
Oui, dans le bon sens du terme : il cadre le LLM. Sans être magique, il force une réponse plus structurée qu’un prompt Kubernetes générique.
Le produit a réellement produit un artefact utile : un manifeste Kubernetes multi-ressources, validable au schéma, avec des garde-fous qui n’étaient pas dans le manifest initial. Pour un freelance sécu ou DevOps, c’est intéressant parce que le skill transforme une demande vague en revue de risques : exposition réseau, ressources, sécurité pod, rollback.
La partie la plus convaincante est la structure. Le skill ne se contente pas de dire “voici du YAML”. Il pousse vers des hypothèses, des modes de panne, des commandes de validation et des notes de rollback. C’est exactement ce qui manque souvent dans les réponses LLM sur Kubernetes.
Les limites de KubeShark
La limite principale : KubeShark reste un skill, donc un cadre de raisonnement. Il ne remplace ni un cluster de test, ni kubectl diff, ni une admission policy, ni une revue humaine.
Mon test a aussi révélé un point important. La deuxième passe a ajouté runAsUser: 1000, mais a gardé nginx sur le port 80. Sur un conteneur non-root, écouter sur un port privilégié peut casser selon l’image. Le schéma Kubernetes est valide, mais le runtime reste à vérifier.
Autre limite : le premier jet était incomplet. Il a amélioré le manifest, mais pas au niveau “production-ready” annoncé. Une boucle de feedback avec des checks statiques a été nécessaire.
Enfin, il n’y a pas d’exécution autonome. Pas de CLI KubeShark qui scanne un dossier, pas de rapport JSON, pas d’intégration directe avec kubectl. Si vous voulez une chaîne fiable, il faut l’entourer avec kubeconform, kube-score, Kyverno, OPA Gatekeeper ou vos propres tests.
Ce que j’aime dans KubeShark
J’aime le format léger. Le dépôt est lisible, les références sont séparées par thème, et le workflow principal tient dans un SKILL.md clair.
J’aime aussi l’approche par modes de panne. C’est beaucoup plus opérationnel qu’une liste vague de bonnes pratiques. Quand on parle Kubernetes, “securityContext” seul ne suffit pas. Il faut penser réseau, rollout, ressources, API, secrets, RBAC et retour arrière.
Autre bon point : l’effort de sobriété token. Les références sont découpées, donc un agent peut charger uniquement ce qui est utile. En théorie, ça évite de noyer le modèle dans toute la documentation Kubernetes.
Ce que je n’aime pas dans KubeShark
Je n’aime pas le nom “KubeShark” si on s’attend à un outil qui observe un cluster. Le nom donne presque l’impression d’un scanner ou d’un analyseur réseau, alors que le projet est un skill de génération et de revue.
Je trouve aussi que la promesse marketing est un peu forte. “Eliminate hallucinations” est trop ambitieux. Mon test montre plutôt “réduit les oublis fréquents, surtout si on boucle avec des validations”. C’est déjà bien, mais ce n’est pas la même promesse.
Dernier point : sans Claude Code ou Codex dans la boucle, il faut bricoler un harness pour tester. Ce n’est pas un problème pour le public visé, mais pour un lecteur grand public, il faut comprendre que l’installation active surtout un comportement d’agent.
Faut-il adopter KubeShark ?
Mon verdict : à essayer si vous utilisez déjà Claude Code ou Codex pour écrire du Kubernetes. Je l’adopterais comme garde-fou de prompt dans un repo infra, surtout pour éviter les manifests nus, sans ressources, sans probes et sans réflexion réseau.
Je ne l’adopterais pas comme outil de validation unique. Le bon usage, selon moi, c’est : KubeShark pour cadrer l’agent, puis validation automatique avec schéma, politiques, tests de déploiement et revue humaine.
Pour une équipe DevOps, c’est utile dans trois cas : génération de brouillons Helm ou YAML, revue rapide de manifests, onboarding de développeurs qui touchent à Kubernetes sans être experts. Pour de la prod sensible, ça doit rester une première ligne de défense, pas le dernier mot.
FAQ
KubeShark installe-t-il quelque chose dans le cluster ?
Non. KubeShark est un skill pour agent de code. Il guide la génération et la revue de manifests, mais il ne déploie rien dans Kubernetes par lui-même.
KubeShark remplace-t-il kubeconform ou Kyverno ?
Non. Il peut suggérer de meilleurs manifests, mais il faut toujours valider avec des outils déterministes. Dans mon test, kubeconform a confirmé le schéma, mais un détail runtime restait à vérifier.
KubeShark vaut-il le coup pour un freelance DevOps ?
Oui, si vous utilisez déjà un agent IA dans vos repos infra. Il aide à structurer les réponses et à éviter des oublis fréquents, mais il faut l’intégrer dans une vraie chaîne de contrôle.