Ongrid is an open source AIOps agent that aims to understand your infrastructure, investigate alerts, and respond from Slack, Telegram, Lark, or DingTalk. My short verdict: the core works, especially the API, authentication, and LLM calls, but the full experience requires a proper observability stack and a connected edge. Worth trying if you want to prototype an SRE copilot, but not something I’d drop blindly onto a client’s production setup.
What is Ongrid?
Ongrid positions itself as an ops agent for teams living inside alerts, logs, metrics, and traces. The idea is straightforward: instead of asking a human to juggle Prometheus, Loki, Tempo, Grafana, SSH, and the team chat, Ongrid serves as an orchestration layer.
The repository includes a Go manager, a React interface, messaging connectors, an IAM foundation, a diagnostic tool inventory, a skills system, and an edge component designed to surface server information without opening inbound ports.
On paper it targets a very concrete need: reducing the time between an alert and an actionable hypothesis. In practice, it is not a small magic binary. It is a full platform.
| Element | What I observed |
|---|---|
| Languages | Go on the manager side, TypeScript and React on the web side |
| Version tested | Release v0.8.6, GitHub repository cloned in parallel |
| Local storage | SQLite possible for a reduced test |
| LLM | OpenAI compatible, tested via local proxy |
| Observability | Designed for Prometheus, Loki, Tempo, Grafana, and Qdrant |
| Channels | Slack, Telegram, Lark, DingTalk, and webhooks per the docs |
Installing Ongrid
The README pushes primarily toward a full server installation with a release archive and install script. I did clone the repository into /tmp, read the code and configuration files, then used the official v0.8.6 archive to actually launch the manager.
The test container did not have Go installed, so I did not recompile from source. I still inspected the code, including the configuration, IAM routes, and AIOps routes. The local launch was done with the official binary, a SQLite database, an admin bootstrap, and the provided LLM proxy.
The relevant configuration looked like this:
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
export OPENAI_API_BASE=http://172.17.0.1:8790/v1
export OPENROUTER_BASE_URL=http://172.17.0.1:8790/v1
export OPENROUTER_API_KEY=sk-proxy
export ONGRID_OPENAI_API_KEY=sk-proxy
export ONGRID_OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export ONGRID_OPENAI_MODEL=openai/gpt-4o-mini
export ONGRID_DB_DIALECT=sqlite
export ONGRID_FRONTIER_DISABLED=true
export ONGRID_PROM_ENABLED=false
I intentionally disabled Frontier and Prometheus to isolate the manager. This is not an ideal installation, but it is a genuine product launch: migrations, admin bootstrap, API routes, LLM catalog, chat sessions, and message storage.
One important thing to know upfront: the API is mounted under /api. Routes like /v1/auth/login do not respond at the root. The correct route is:
POST /api/v1/auth/login
Using Ongrid
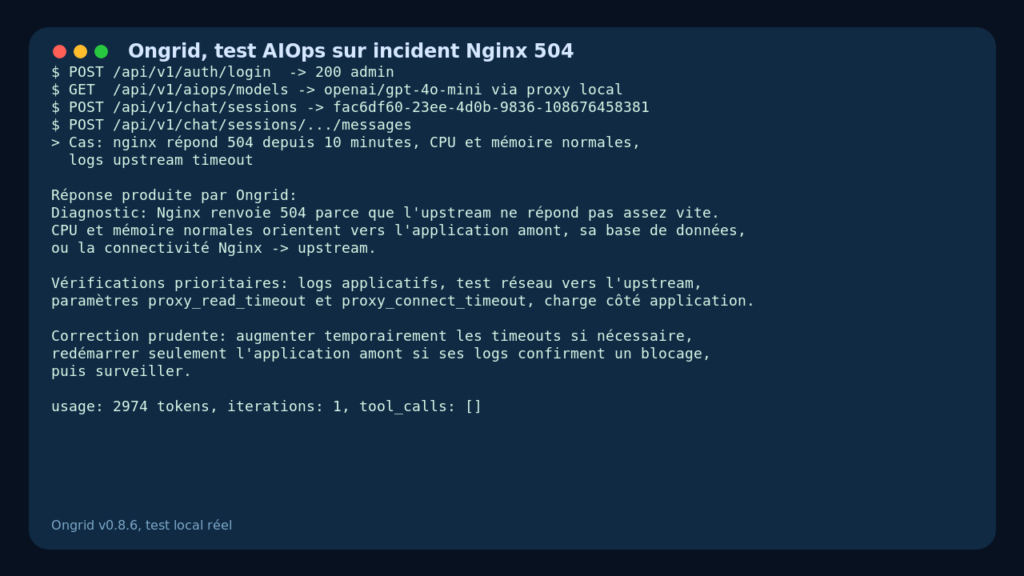
My concrete use case: simulate an SRE request around an Nginx incident. The scenario was deliberately realistic and fairly classic: Nginx returning 504s for ten minutes, normal CPU, normal memory, logs showing upstream timeout.
I first validated the model catalog:
GET /api/v1/aiops/models
Ongrid properly exposed the OpenAI-compatible provider with openai/gpt-4o-mini as the default model. I then created a chat session:
POST /api/v1/chat/sessions
Then sent the incident message to the session:
POST /api/v1/chat/sessions/{id}/messages
What I observed was not a simple server startup. Ongrid produced a stored assistant response, with a message identifier, the model used, token counters, and an agent iteration.
The response identified the main lead: Nginx is not getting a fast enough response from the upstream. It suggested checking application logs, connectivity between Nginx and the upstream, the proxy_read_timeout and proxy_connect_timeout settings, then fixing things carefully without blindly restarting the whole machine.
This is not a deep RCA, since no real edge, no Prometheus metrics, and no Loki were connected. But it is a working flow: auth, session, LLM call, response, persistence.
Does Ongrid actually work?
Yes, within the scope I was able to run cleanly. The manager starts, migrates its database, creates the admin, exposes routes, accepts login, lists models, and responds via the LLM.
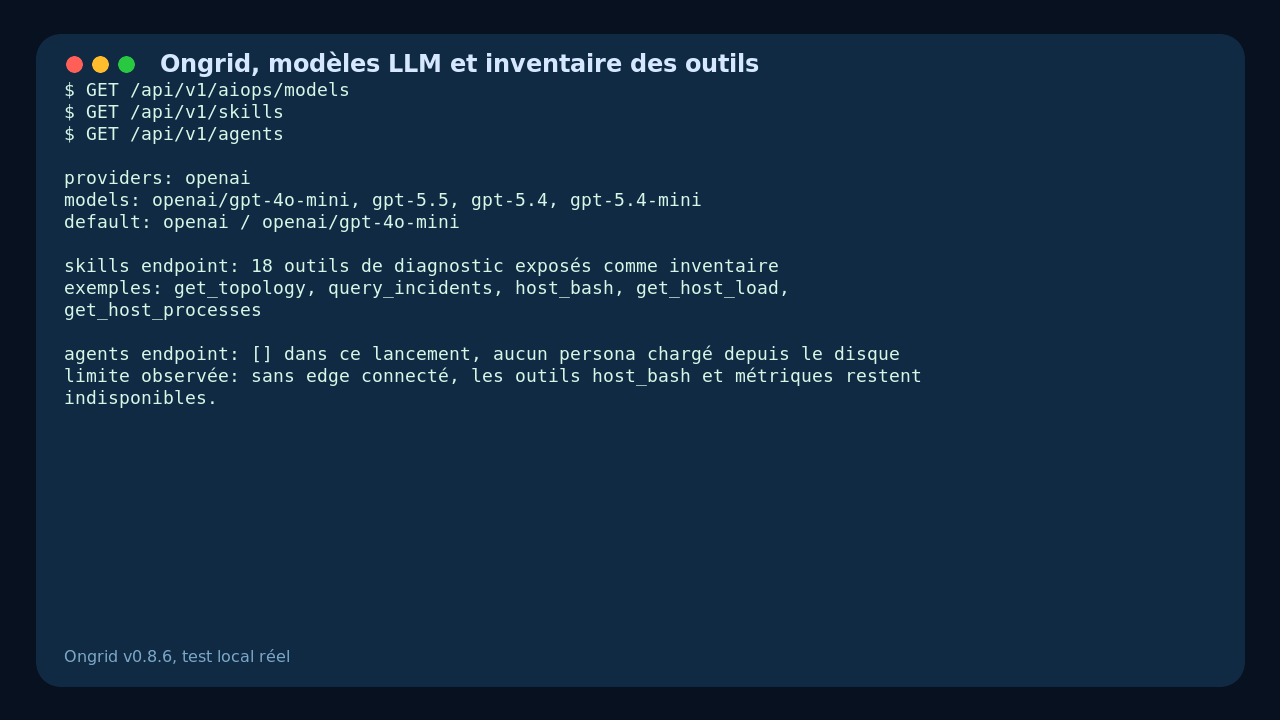
I also queried the skills inventory. Ongrid exposes tools like get_topology, query_incidents, host_bash, get_host_load, and get_host_processes. This is where the project gets interesting for a DevOps engineer: the model is not just a chatbot, it is supposed to have structured tools available for diagnosis.
But to be honest: in my reduced local test, those tools are mostly just an inventory. Without a connected edge, a full observability stack, and real production or lab data, Ongrid cannot actually read a real journalctl, query a real metric, or correlate a real incident.
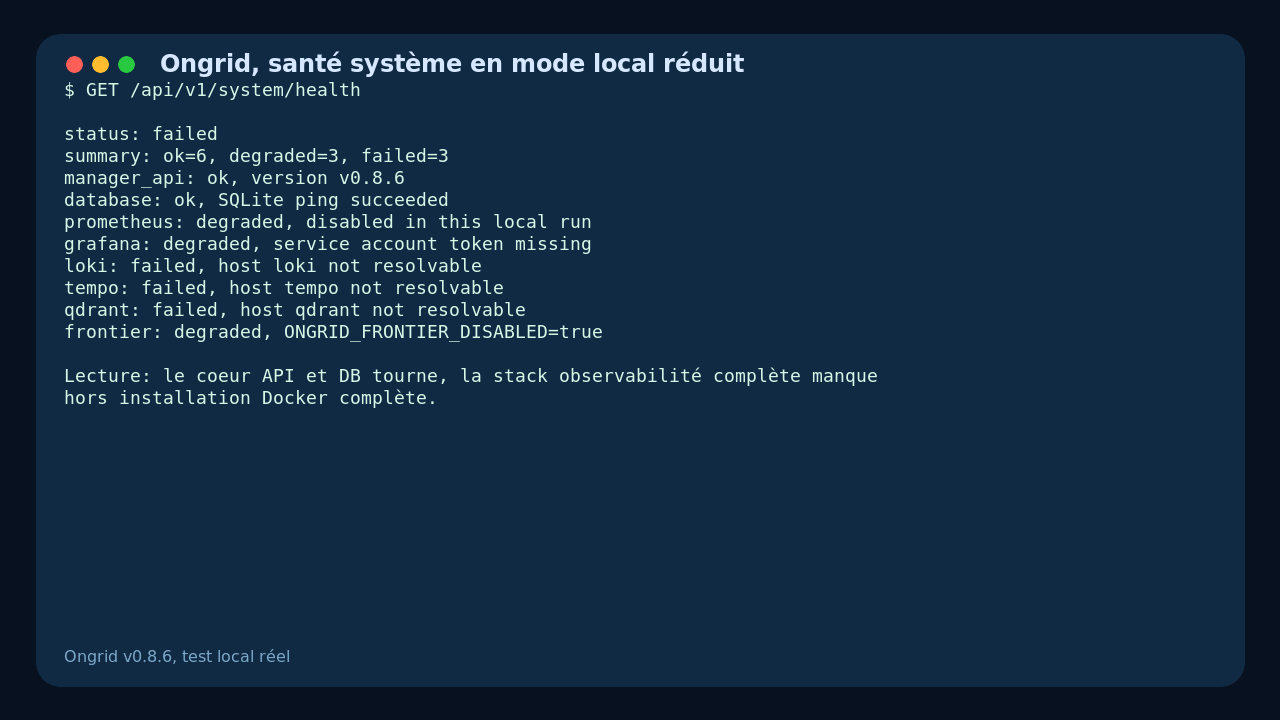
The health page shows this clearly: the manager and SQLite are OK, but Loki, Tempo, and Qdrant fail, Prometheus is disabled, Grafana has no token, and Frontier is off.
What I like about Ongrid
First, the technical ambition. Ongrid is not selling just a chat wrapper around an LLM. The code shows a genuine intent to structure an ops agent: IAM, audit, sessions, model catalog, observability integration, messaging connectors, edge, skills, and tools.
I also appreciate the clean API design. For a tester or integrator, being able to drive /api/v1/chat/sessions and /api/v1/aiops/models directly is genuinely useful. You can automate a scenario without depending on a UI.
SQLite mode is handy for a quick trial. Even though the installation docs target a heavier stack, I was able to launch the manager without MySQL and observe real behavior.
Finally, the inbound-port-free edge approach is relevant. For a security or DevOps freelancer, that kind of detail matters. An ops agent that requires opening SSH or an admin port everywhere quickly becomes a security problem.
The limits of Ongrid
The first limit is weight. The release archive is large, a full installation bundles a lot of components, and the product only really makes sense with Prometheus, Loki, Tempo, Grafana, Qdrant, and Frontier. This is not something I would spin up on a random VPS without reading the scripts carefully.
The second limit is experience maturity. In my test, several default values pointed to internal hosts like loki, tempo, or qdrant. That makes sense inside Docker Compose, but it is noisy in a reduced local setup. The health endpoint turns red even when the manager core is working fine.
The third limit is diagnosis without data. The Nginx response was correct but generic. To go from a good SRE checklist to a useful RCA, Ongrid needs access to metrics, logs, traces, topology, and read-only commands on the hosts.
One last thing: I did not validate the full loop from Slack or Telegram, nor the edge on a remote machine. My test proves the manager works and that an AIOps interaction via API is functional, not the product across its full marketing promise.
Should you adopt Ongrid?
My verdict: try it, do not adopt it directly in production.
For a curious infra team, Ongrid is worth a lab setup. There is enough substance in the repository to justify a serious test: API, agents, skills, observability, channels, edge. If you already have Prometheus, Loki, and Grafana, you can picture a useful POC around a staging environment.
For a small team without a clean observability stack, I would start elsewhere. Ongrid does not eliminate the need to instrument your infrastructure. It makes it more actionable once the data is available.
For my own security and DevOps freelance work, I would classify it as an interesting open source AIOps building block, still worth watching. The potential is real, and so is the integration cost.
FAQ
Does Ongrid replace Prometheus or Grafana?
No. Ongrid relies on those tools to query metrics, logs, traces, and dashboards. Without observability data, the agent can still respond, but its diagnosis stays much more generic.
Can you test Ongrid without a real OpenAI key?
Yes, if you have an OpenAI-compatible endpoint. In my test I used a local proxy with ONGRID_OPENAI_BASE_URL and ONGRID_OPENAI_API_KEY, then the model openai/gpt-4o-mini.
Is Ongrid production-ready?
I would not deploy it directly at a client’s site without a POC, a review of the install scripts, access control checks, and edge testing. For an AIOps lab or staging environment, though, the project clearly deserves a try.