Ongrid est un agent AIOps open source qui veut comprendre une infra, enquêter sur les alertes et répondre depuis Slack, Telegram, Lark ou DingTalk. Mon verdict court : le cœur fonctionne, surtout l’API, l’authentification et l’appel LLM, mais l’expérience complète demande une vraie stack d’observabilité et un edge connecté. À essayer si vous voulez prototyper un copilote SRE, pas encore à poser les yeux fermés sur une production client.
Ongrid, c’est quoi ?
Ongrid se présente comme un agent ops pour les équipes qui vivent dans les alertes, les logs, les métriques et les traces. L’idée est simple : au lieu de demander à un humain de jongler entre Prometheus, Loki, Tempo, Grafana, SSH et le chat d’équipe, Ongrid sert de couche d’orchestration.
Dans le dépôt, on trouve un manager Go, une interface React, des connecteurs de messagerie, une base IAM, un inventaire d’outils de diagnostic, un système de skills, et un composant edge censé remonter les informations des serveurs sans ouvrir de port entrant.
Sur le papier, ça vise un besoin très concret : réduire le temps entre une alerte et une hypothèse exploitable. En pratique, ce n’est pas un petit binaire magique. C’est une plateforme complète.
| Élément | Ce que j’ai constaté |
|---|---|
| Langages | Go côté manager, TypeScript et React côté web |
| Version testée | Release v0.8.6, dépôt GitHub cloné en parallèle |
| Stockage local | SQLite possible pour un test réduit |
| LLM | OpenAI compatible, testé via proxy local |
| Observabilité | Prévue pour Prometheus, Loki, Tempo, Grafana et Qdrant |
| Canaux | Slack, Telegram, Lark, DingTalk et webhooks selon la doc |
Installation de Ongrid
Le README pousse surtout vers une installation serveur complète avec archive de release et script d’installation. J’ai bien cloné le dépôt dans /tmp, lu le code et les fichiers de configuration, puis j’ai utilisé l’archive officielle v0.8.6 pour lancer le manager réellement.
Le conteneur de test n’avait pas Go installé, donc je n’ai pas recompilé depuis les sources. J’ai tout de même inspecté le code, notamment la configuration, les routes IAM et les routes AIOps. Le lancement local a été fait avec le binaire officiel, une base SQLite, un admin bootstrap et le proxy LLM fourni.
La configuration utile ressemblait à ceci :
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
export OPENAI_API_BASE=http://172.17.0.1:8790/v1
export OPENROUTER_BASE_URL=http://172.17.0.1:8790/v1
export OPENROUTER_API_KEY=sk-proxy
export ONGRID_OPENAI_API_KEY=sk-proxy
export ONGRID_OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export ONGRID_OPENAI_MODEL=openai/gpt-4o-mini
export ONGRID_DB_DIALECT=sqlite
export ONGRID_FRONTIER_DISABLED=true
export ONGRID_PROM_ENABLED=false
J’ai volontairement désactivé Frontier et Prometheus pour isoler le manager. Ce n’est pas l’installation idéale, mais c’est un vrai lancement du produit : migrations, bootstrap admin, routes API, catalogue LLM, sessions chat et stockage des messages.
Premier point important : l’API est montée sous /api. Les routes comme /v1/auth/login ne répondent pas à la racine. La route correcte est donc :
POST /api/v1/auth/login
Ongrid à l’usage
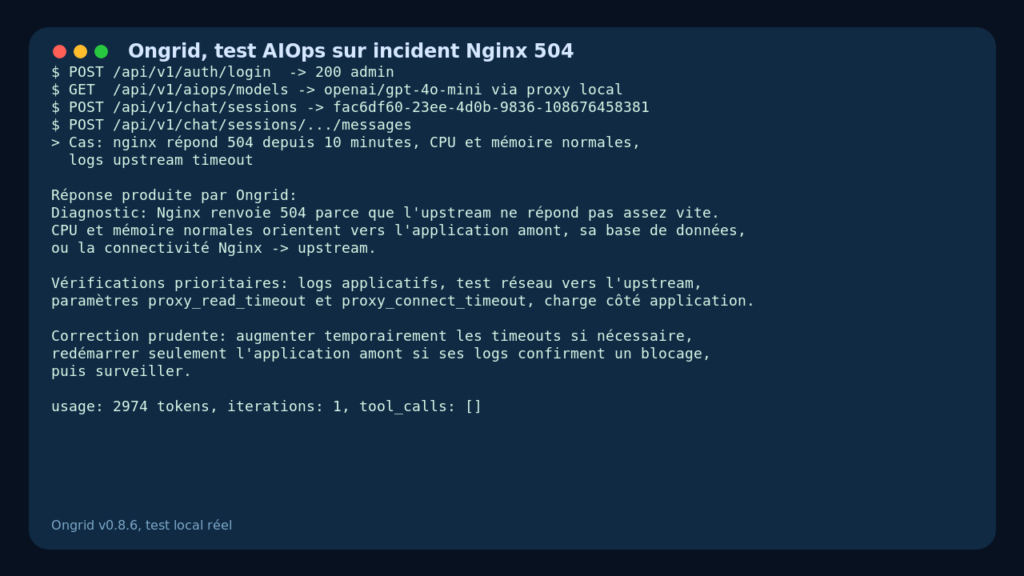
Mon cas d’usage concret : simuler une demande SRE sur un incident Nginx. Le scénario était volontairement réaliste et assez classique : Nginx répond en 504 depuis dix minutes, CPU normale, mémoire normale, logs avec upstream timeout.
J’ai d’abord validé le catalogue de modèles :
GET /api/v1/aiops/models
Ongrid a bien exposé le provider OpenAI compatible avec openai/gpt-4o-mini comme modèle par défaut. Ensuite, j’ai créé une session de chat :
POST /api/v1/chat/sessions
Puis j’ai envoyé le message d’incident à la session :
POST /api/v1/chat/sessions/{id}/messages
Le résultat observé n’est pas un simple démarrage serveur. Ongrid a produit une réponse assistant stockée, avec un identifiant de message, le modèle utilisé, les compteurs de tokens et une itération agent.
La réponse a identifié la piste principale : Nginx ne reçoit pas de réponse assez vite de l’upstream. Elle a proposé de vérifier les logs applicatifs, la connectivité entre Nginx et l’amont, les paramètres proxy_read_timeout et proxy_connect_timeout, puis de corriger prudemment sans redémarrage aveugle de toute la machine.
Ce n’est pas une RCA profonde, car aucun edge réel, aucune métrique Prometheus et aucun Loki n’étaient connectés. Mais c’est bien un flux fonctionnel : auth, session, appel LLM, réponse, persistance.
Ongrid, est-ce que ça marche vraiment ?
Oui, dans le périmètre que j’ai pu faire tourner proprement. Le manager démarre, migre sa base, crée l’admin, expose les routes, accepte le login, liste les modèles et répond via le LLM.
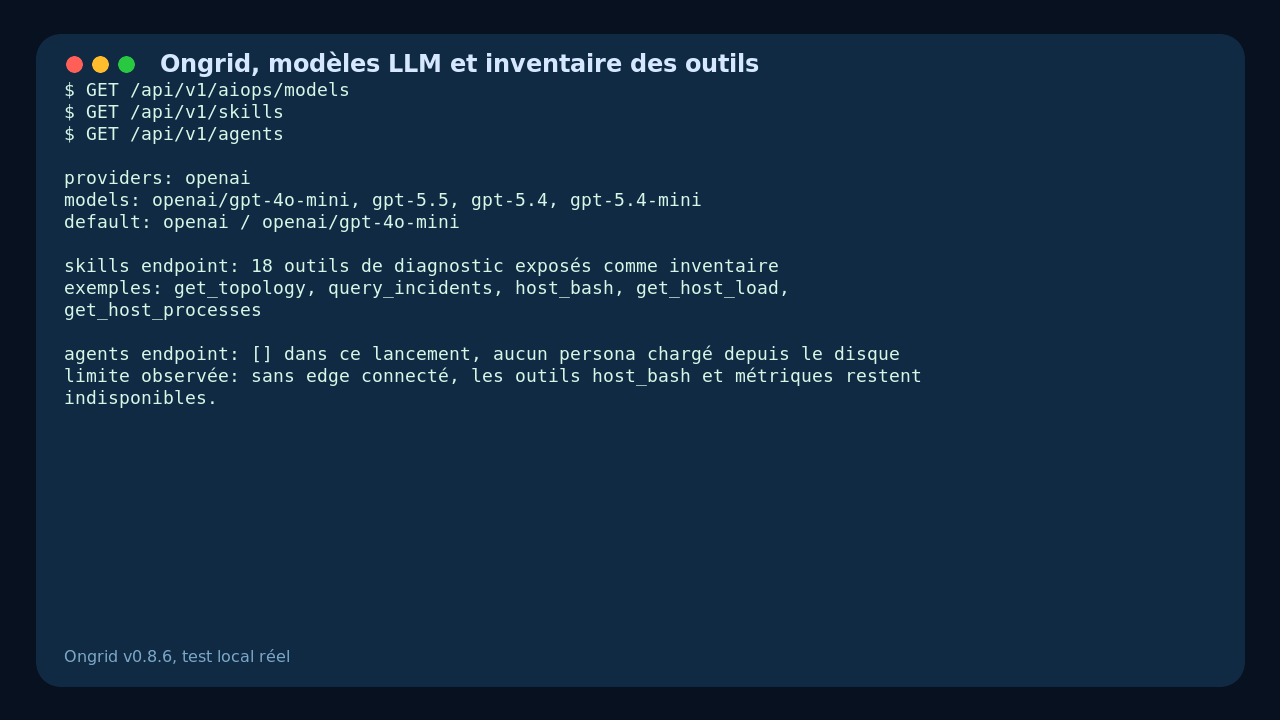
J’ai aussi interrogé l’inventaire des skills. Ongrid expose des outils comme get_topology, query_incidents, host_bash, get_host_load et get_host_processes. C’est là que le projet devient intéressant pour un DevOps : le modèle n’est pas seulement un chatbot, il est censé disposer d’outils structurés pour diagnostiquer.
Mais il faut être honnête : dans mon test local réduit, ces outils restent surtout un inventaire. Sans edge connecté, sans stack observabilité complète et sans données de prod ou de lab, Ongrid ne peut pas aller lire un vrai journalctl, interroger une vraie métrique ou corréler un incident réel.
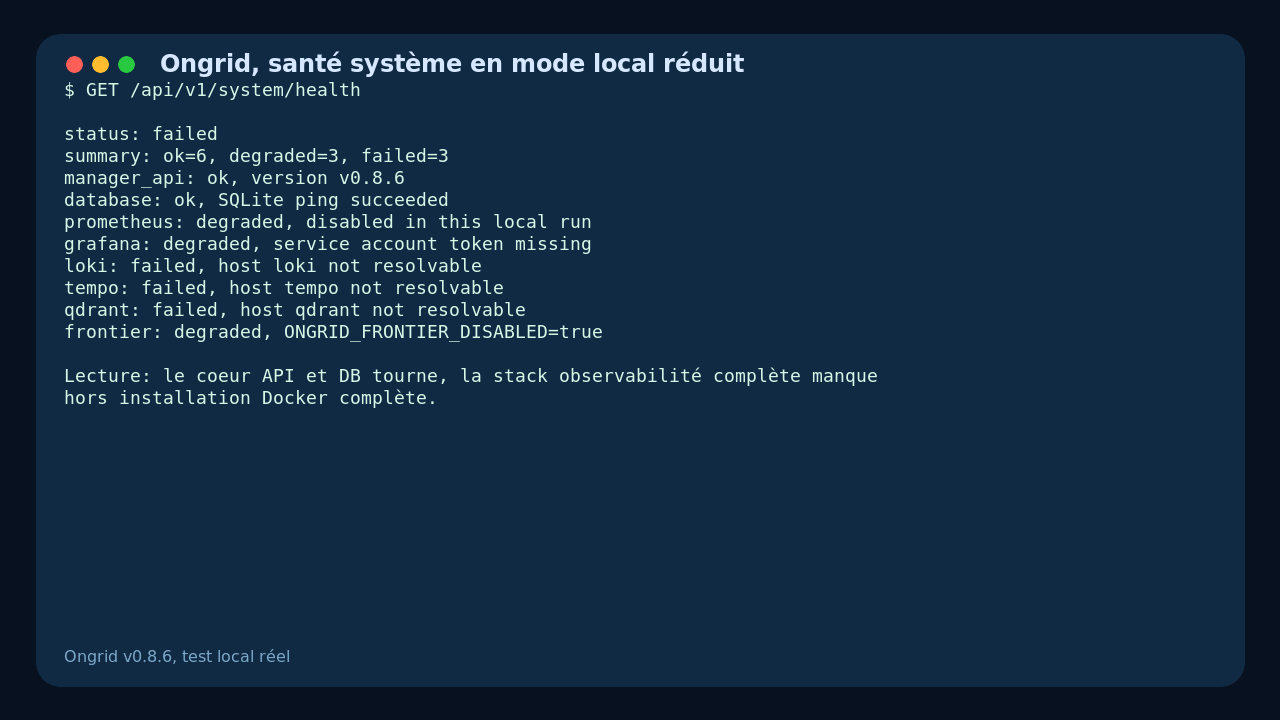
La page santé le montre très bien : le manager et SQLite sont OK, mais Loki, Tempo et Qdrant échouent, Prometheus est désactivé, Grafana n’a pas de token, et Frontier est coupé.
Ce que j’aime dans Ongrid
J’aime d’abord l’ambition technique. Ongrid ne vend pas seulement un wrapper de chat autour d’un LLM. Le code montre une vraie volonté de structurer un agent ops : IAM, audit, sessions, catalogue de modèles, intégration observabilité, connecteurs de messagerie, edge, skills et outils.
J’aime aussi le choix d’une API claire. Pour un testeur ou un intégrateur, pouvoir piloter /api/v1/chat/sessions et /api/v1/aiops/models directement est appréciable. On peut automatiser un scénario sans dépendre d’une UI.
Le mode SQLite est pratique pour un essai. Même si la doc d’installation vise une stack plus lourde, j’ai pu lancer le manager sans MySQL et observer un vrai comportement.
Enfin, l’approche edge sans port entrant est pertinente. Pour un freelance sécu ou DevOps, c’est le genre de détail qui compte. Un agent ops qui exige d’ouvrir SSH ou un port d’admin partout devient vite un problème de sécurité.
Les limites de Ongrid
La première limite est la lourdeur. L’archive de release est grosse, l’installation complète embarque beaucoup de composants, et le produit prend vraiment son sens avec Prometheus, Loki, Tempo, Grafana, Qdrant et Frontier. Ce n’est pas un outil que je lancerais sur un coin de VPS sans lire les scripts.
La deuxième limite est la maturité d’expérience. Dans mon test, plusieurs valeurs par défaut pointaient vers des hôtes internes comme loki, tempo ou qdrant. C’est logique dans Docker Compose, mais bruyant en mode local réduit. L’endpoint santé devient alors rouge, même si le cœur du manager fonctionne.
La troisième limite est le diagnostic sans données. La réponse sur Nginx était correcte, mais générique. Pour passer de “bonne check-list SRE” à “RCA utile”, Ongrid doit avoir accès aux métriques, logs, traces, topologie et commandes read-only sur les hôtes.
Dernier point : je n’ai pas validé la boucle complète depuis Slack ou Telegram, ni l’edge sur une machine distante. Mon test prouve le fonctionnement du manager et d’une interaction AIOps via API, pas le produit dans toute sa promesse marketing.
Faut-il adopter Ongrid ?
Mon verdict : essayer, pas adopter directement en production.
Pour une équipe infra curieuse, Ongrid vaut un lab. Il y a assez de substance dans le dépôt pour justifier un test sérieux : API, agents, skills, observabilité, canaux, edge. Si vous avez déjà Prometheus, Loki et Grafana, vous pouvez imaginer un POC utile autour d’un environnement de staging.
Pour une petite équipe sans stack observabilité propre, je commencerais ailleurs. Ongrid n’élimine pas le besoin d’instrumenter l’infra. Il le rend plus exploitable une fois les données disponibles.
Pour mon usage freelance sécu et DevOps, je le classerais comme une brique intéressante d’AIOps open source, encore à surveiller. Le potentiel est réel, mais le coût d’intégration aussi.
FAQ
Ongrid remplace-t-il Prometheus ou Grafana ?
Non. Ongrid s’appuie plutôt sur ces briques pour interroger les métriques, logs, traces et dashboards. Sans données observabilité, l’agent peut répondre, mais son diagnostic reste beaucoup plus générique.
Peut-on tester Ongrid sans clé OpenAI réelle ?
Oui, si vous avez un endpoint compatible OpenAI. Dans mon test, j’ai utilisé un proxy local avec ONGRID_OPENAI_BASE_URL et ONGRID_OPENAI_API_KEY, puis le modèle openai/gpt-4o-mini.
Ongrid est-il prêt pour la production ?
Je ne le déploierais pas directement chez un client sans POC, revue des scripts d’installation, contrôle des accès et test de l’edge. En revanche, pour un lab AIOps ou un staging, le projet mérite clairement un essai.