Local memory for agents, tested on a real mini dataset
TencentDB Agent Memory is a long-term memory plugin for AI agents. The idea: capture conversations, extract structured memories, group those memories into scenes, then produce a readable user profile.
This is not just a vector store sitting next to a chatbot. The project pushes a layered logic:
| Layer | Role | What I saw |
|---|---|---|
| L0 | Raw conversations | Local JSONL plus rows in SQLite |
| L1 | Structured memories | 7 memories extracted with type, priority, scene |
| L2 | Scenes | 1 scene_blocks/*.md file generated |
| L3 | Persona | 1 persona.md generated and readable |
| Storage | Local | vectors.db, JSONL, Markdown |
| Runtime | Node | Node 22 required, Node 20 is not enough |
The repo targets OpenClaw primarily, with a Hermes integration announced in the README. For this test, I ran it as a seed pipeline, directly from the repo code, to inject a real historical conversation and see what it produces.

What I actually tried
I cloned the repo into /tmp, read the README, the package.json, the seed CLI, then installed and built the project.
First real-world constraint: /tmp is mounted with noexec in my environment, and the project requires Node >=22.16. The machine had Node 20. So I kept the clone in /tmp, then used a temporary scratch directory under the output root to install and run with Node 22 via npx node@22. The scratch directory was deleted at the end.
Representative commands:
git clone https://github.com/TencentCloud/TencentDB-Agent-Memory.git /tmp/TencentDB-Agent-Memory
cd /workspace/scout-tencentcloud-tencentdb-agent-memor/.tmp/repo
npx -y node@22 /usr/local/bin/npm install
npx -y node@22 /usr/local/bin/npm run build
npx -y node@22 /usr/local/bin/npm test
Build and test results:
Build complete in 244ms
Test Files 1 passed (1)
Tests 38 passed (38)
Then I injected a 6-turn conversation on a concrete case: an internal assistant for a security and DevOps freelancer, covering editorial preferences, tech stack, server operation constraints, and GitHub scout evaluation criteria.
Before running, I configured the required local OpenAI-compatible proxy:
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
export OPENAI_API_BASE=http://172.17.0.1:8790/v1
export OPENROUTER_BASE_URL=http://172.17.0.1:8790/v1
export OPENROUTER_API_KEY=sk-proxy
Plugin configuration used:
{
"llm": {
"enabled": true,
"baseUrl": "http://172.17.0.1:8790/v1",
"apiKey": "sk-proxy",
"model": "openai/gpt-4o-mini"
},
"storeBackend": "sqlite",
"embedding": { "provider": "none", "enabled": false },
"pipeline": {
"everyNConversations": 2,
"enableWarmup": false,
"l1IdleTimeoutSeconds": 1,
"l2DelayAfterL1Seconds": 1,
"l2MinIntervalSeconds": 1,
"l2MaxIntervalSeconds": 3
},
"persona": { "triggerEveryN": 3 }
}
I disabled embeddings to test the local FTS path and avoid depending on an embedding endpoint. This matters: the product still keeps data in SQLite and allows full-text search.
What it produced
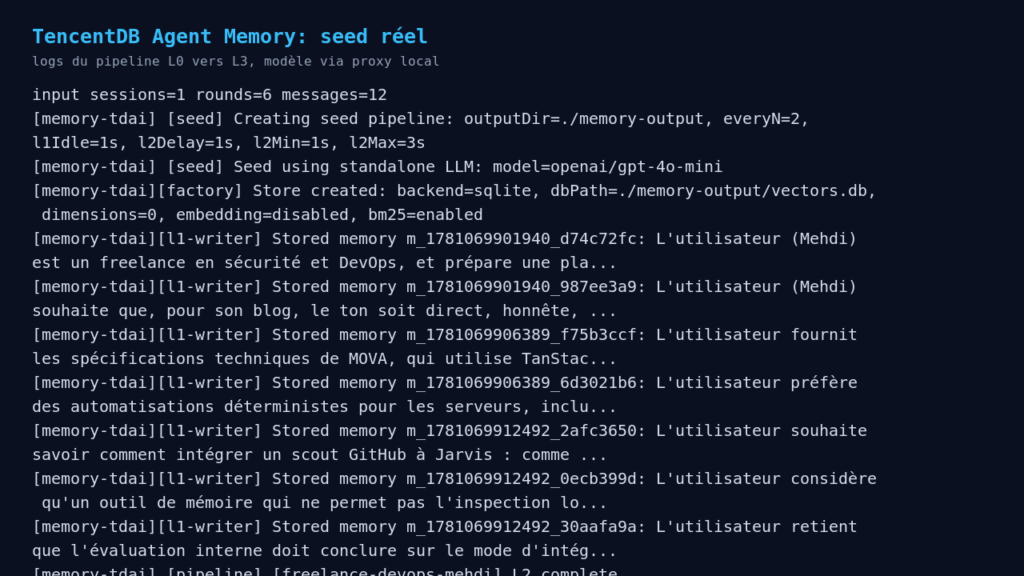
The pipeline actually processed the conversation:
sessionsProcessed: 1
roundsProcessed: 6
messagesProcessed: 12
l0RecordedCount: 12
Generated files:
.metadata/manifest.json
.metadata/recall_checkpoint.json
.metadata/scene_index.json
conversations/2026-06-10.jsonl
records/2026-06-10.jsonl
scene_blocks/Freelance-in-Security-and-DevOps.md
persona.md
vectors.db
L1 extracted 7 memories. Sample of the actual output:

Examples of extracted memories:
[instruction] L'utilisateur (Mehdi) souhaite que, pour son blog, le ton soit direct, honnête, sans hype marketing, sans jargon gratuit et sans promesse magique.
[persona] L'utilisateur préfère des automatisations déterministes pour les serveurs, incluant health checks, journaux, rollback, et self-heal sous garde, avec des actions auditables.
[instruction] L'utilisateur considère qu'un outil de mémoire qui ne permet pas l'inspection locale des données ou l'export est un mauvais signal.
I also tested memory search with a deliberately mixed query:
tdai_memory_search "blog hype inspectable export Jarvis"
Result: 4 relevant memories retrieved, including blog tone, local inspection requirement, the Jarvis integration question, and the security and DevOps freelance context.
Finally, the pipeline produced a persona and a Markdown scene block:

The persona.md file is readable, versionable, and contains a usable summary. The scene block also keeps a summary with an index.
What I like
The data is inspectable
This is the biggest strength. You are not left with opaque memory locked inside an external service. Here, you get local files, a SQLite database, JSONL files, Markdown.
For a security or DevOps profile, that is reassuring. You can audit, back up, delete, export, and diff everything.
The pipeline does not just stack chunks
The project tries to structure memory:
- raw facts,
- atomic memories,
- scenes,
- persona.
That is more ambitious than a simple vector search over old messages.
The no-embeddings mode is still useful
With embeddings disabled, I still got:
- L0 capture,
- L1 extraction by LLM,
- FTS search,
- L2 scene,
- L3 persona.
That enables a local and lightweight mode, especially useful for sensitive data.
The logs are detailed
The pipeline narrates what it is doing: capture, indexing, extraction, L2 timers, persona generation, checkpoints. Helpful for diagnosing issues.
What I do not like and the limitations
Standalone integration is not very smooth yet
The README focuses mostly on OpenClaw and Hermes. The seed CLI exists in the code, but using it directly outside OpenClaw requires understanding the internal modules.
For a developer-facing product, I would have liked a clear standalone command, something like:
memory-tdai seed --input conversations.json --output-dir ./memory-output
Node 22 is required
The project uses node:sqlite, so Node 22 makes sense. But in practice, it breaks quickly on environments still running Node 20.
I would not call this a blocking flaw, more a constraint that needs to be very clearly communicated.
The seed shutdown could be cleaner
In my run, the end of the seed displayed a pipeline flush timeout, with a message saying pending work would be recovered on the next startup.
Despite that, the L2 and L3 files were correctly written after the summary. It works, but the operator experience feels a bit fuzzy: you want to know precisely whether the job is done or still finalizing.
The postinstall tries to patch OpenClaw
During npm install, the postinstall attempted to patch OpenClaw, then failed cleanly because OpenClaw was not installed. The installation continued.
Not a big deal, but it is surprising in a standalone test.
Does it actually work?
Yes, in this test, it works.
Not just in the sense of “it starts.” The product:
- captured 12 messages,
- wrote L0,
- extracted 7 L1 memories,
- retrieved memories via FTS search,
- generated a scene block,
- generated a
persona.md, - stored everything locally.
Memory quality was solid. The important information was captured: editorial tone, tech stack, deterministic DevOps posture, local inspection requirement, Jarvis context.
I would not draw conclusions from the README’s performance numbers yet. I did not replay their benchmarks. My test mainly validates functional usefulness on a small concrete case.
Who this is useful for
Worth trying if you are building a long-term agent
If you are developing an assistant that needs to remember preferences, project constraints, decisions, and work sessions, this is interesting.
Especially if you want to keep memory local and inspectable.
Relevant for agent teams, infra, and internal tooling
I can see this fitting well for:
- internal DevOps assistants,
- technical support agents,
- research copilots,
- knowledge management pipelines,
- environments where traceability matters.
Less suited if you want a minimal SDK
If you are looking for a very simple library you can call with three functions, this is not that yet. The project feels more like a system plugin for agents than a small application dependency.
Verdict
Try it.
I would not say “adopt everywhere” yet, because the ergonomics outside OpenClaw are still rough and the L2/L3 cycle deserves a cleaner job completion signal.
But the core works, and it produces something concrete: structured memories, scenes, a persona, all local and inspectable.
For a serious agent, this layered approach is healthier than a big bag of vector chunks. It is exactly the kind of building block I keep on my short list when I need to give memory to an autonomous assistant without losing control of the data.