Une mémoire locale pour agents, testée sur un vrai mini dossier
TencentDB Agent Memory est un plugin de mémoire longue durée pour agents IA. L’idée: capturer les conversations, extraire des souvenirs structurés, regrouper ces souvenirs en scènes, puis produire un profil utilisateur lisible.
Ce n’est pas juste un vector store posé à côté d’un chatbot. Le projet pousse une logique en couches:
| Couche | Rôle | Ce que j’ai vu |
|---|---|---|
| L0 | Conversations brutes | JSONL local plus lignes dans SQLite |
| L1 | Souvenirs structurés | 7 mémoires extraites avec type, priorité, scène |
| L2 | Scènes | 1 fichier scene_blocks/*.md généré |
| L3 | Persona | 1 persona.md généré et lisible |
| Stockage | Local | vectors.db, JSONL, Markdown |
| Runtime | Node | Node 22 requis, Node 20 ne suffit pas |
Le dépôt cible surtout OpenClaw, avec une intégration Hermes annoncée dans le README. Pour ce test, je l’ai lancé comme pipeline de seed, à partir du code du repo, pour injecter une vraie conversation historique et voir ce qu’il produit.

Ce que j’ai essayé concrètement
J’ai cloné le dépôt dans /tmp, lu le README, le package.json, le CLI seed, puis installé et buildé le projet.
Première contrainte terrain: /tmp est monté en noexec dans mon environnement, et le projet demande Node >=22.16. La machine avait Node 20. J’ai donc gardé le clone dans /tmp, puis utilisé un scratch temporaire sous la racine de sortie pour installer et exécuter avec Node 22 via npx node@22. Le scratch a été supprimé à la fin.
Commandes représentatives:
git clone https://github.com/TencentCloud/TencentDB-Agent-Memory.git /tmp/TencentDB-Agent-Memory
cd /workspace/scout-tencentcloud-tencentdb-agent-memor/.tmp/repo
npx -y node@22 /usr/local/bin/npm install
npx -y node@22 /usr/local/bin/npm run build
npx -y node@22 /usr/local/bin/npm test
Résultat build et tests:
Build complete in 244ms
Test Files 1 passed (1)
Tests 38 passed (38)
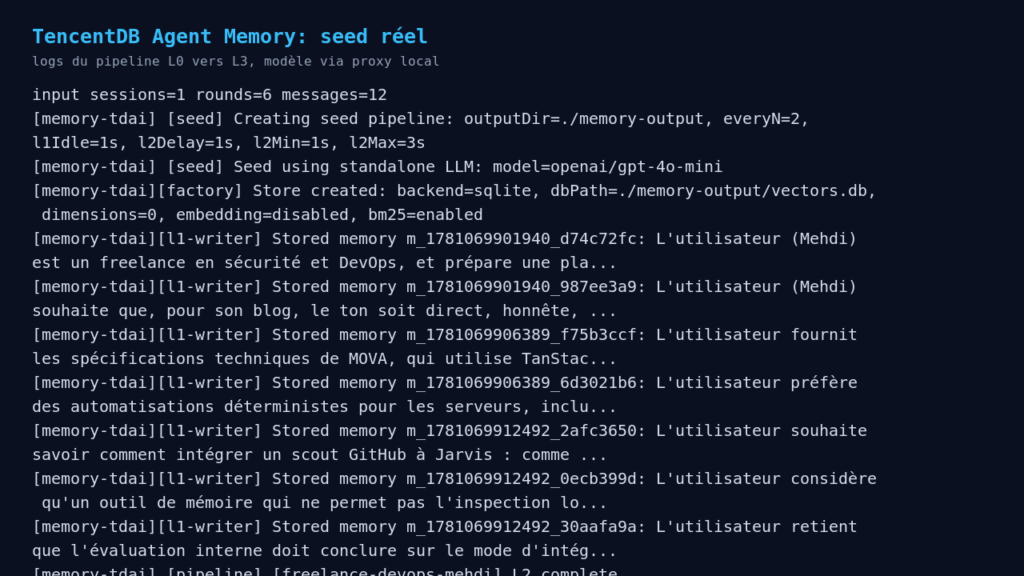
Ensuite, j’ai injecté une conversation de 6 tours sur un cas concret: un assistant interne de freelance sécu et DevOps, avec préférences éditoriales, stack technique, contraintes d’exploitation serveur, et critères d’évaluation d’un scout GitHub.
Avant de lancer, j’ai configuré le proxy local OpenAI compatible demandé:
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
export OPENAI_API_BASE=http://172.17.0.1:8790/v1
export OPENROUTER_BASE_URL=http://172.17.0.1:8790/v1
export OPENROUTER_API_KEY=sk-proxy
Configuration utilisée côté plugin:
{
"llm": {
"enabled": true,
"baseUrl": "http://172.17.0.1:8790/v1",
"apiKey": "sk-proxy",
"model": "openai/gpt-4o-mini"
},
"storeBackend": "sqlite",
"embedding": { "provider": "none", "enabled": false },
"pipeline": {
"everyNConversations": 2,
"enableWarmup": false,
"l1IdleTimeoutSeconds": 1,
"l2DelayAfterL1Seconds": 1,
"l2MinIntervalSeconds": 1,
"l2MaxIntervalSeconds": 3
},
"persona": { "triggerEveryN": 3 }
}
J’ai désactivé les embeddings pour tester le chemin local FTS et éviter de dépendre d’un endpoint d’embedding. C’est important: le produit garde quand même les données en SQLite et permet une recherche textuelle.
Ce que ça a produit
Le pipeline a réellement traité la conversation:
sessionsProcessed: 1
roundsProcessed: 6
messagesProcessed: 12
l0RecordedCount: 12
Fichiers générés:
.metadata/manifest.json
.metadata/recall_checkpoint.json
.metadata/scene_index.json
conversations/2026-06-10.jsonl
records/2026-06-10.jsonl
scene_blocks/Freelance-in-Security-and-DevOps.md
persona.md
vectors.db
Le L1 a extrait 7 souvenirs. Exemple de sortie réelle:

Exemples de souvenirs extraits:
[instruction] L'utilisateur (Mehdi) souhaite que, pour son blog, le ton soit direct, honnête, sans hype marketing, sans jargon gratuit et sans promesse magique.
[persona] L'utilisateur préfère des automatisations déterministes pour les serveurs, incluant health checks, journaux, rollback, et self-heal sous garde, avec des actions auditables.
[instruction] L'utilisateur considère qu'un outil de mémoire qui ne permet pas l'inspection locale des données ou l'export est un mauvais signal.
J’ai aussi testé la recherche mémoire sur une requête volontairement mélangée:
tdai_memory_search "blog hype inspectable export Jarvis"
Résultat: 4 mémoires pertinentes retrouvées, dont le ton blog, l’exigence d’inspection locale, la question d’intégration Jarvis, et le contexte freelance sécu et DevOps.
Enfin, le pipeline a produit une persona et un bloc de scène Markdown:

Le fichier persona.md est lisible, versionnable, et contient une synthèse exploitable. Le bloc de scène garde aussi un résumé avec un index.
Ce que j’aime
Les données sont inspectables
C’est le gros point fort. On ne se retrouve pas avec une mémoire opaque coincée dans un service externe. Ici, j’ai des fichiers locaux, une base SQLite, des JSONL, des Markdown.
Pour un profil sécu ou DevOps, c’est rassurant. On peut auditer, sauvegarder, supprimer, exporter, diff-er.
Le pipeline n’empile pas juste des chunks
Le projet essaie de structurer la mémoire:
- faits bruts,
- souvenirs atomiques,
- scènes,
- persona.
C’est plus ambitieux qu’une simple recherche vectorielle sur les anciens messages.
Le mode sans embeddings reste utile
En désactivant les embeddings, j’ai quand même obtenu:
- capture L0,
- extraction L1 par LLM,
- recherche FTS,
- scène L2,
- persona L3.
Ça permet un mode local et sobre, surtout pour des données sensibles.
Les logs sont détaillés
Le pipeline raconte ce qu’il fait: capture, indexation, extraction, timers L2, génération persona, checkpoints. Pour diagnostiquer, c’est bienvenu.
Ce que je n’aime pas et les limites
L’intégration autonome n’est pas encore très douce
Le README met surtout en avant OpenClaw et Hermes. Le CLI seed existe dans le code, mais son usage direct hors OpenClaw demande de comprendre les modules internes.
Pour un produit grand public développeur, j’aurais aimé une commande autonome claire, par exemple:
memory-tdai seed --input conversations.json --output-dir ./memory-output
Node 22 obligatoire
Le projet utilise node:sqlite, donc Node 22 est logique. Mais en pratique, ça casse vite sur des environnements encore en Node 20.
Je ne considère pas ça comme un défaut bloquant, plutôt comme une contrainte à afficher très clairement.
Le shutdown du seed est perfectible
Dans mon run, la fin du seed a affiché un timeout de flush pipeline, avec un message indiquant que du travail pending serait récupéré au prochain démarrage.
Malgré ça, les fichiers L2 et L3 ont bien été écrits après le résumé. C’est fonctionnel, mais le ressenti opérateur est un peu flou: on veut savoir précisément si le job est fini ou encore en train de finaliser.
Le postinstall tente un patch OpenClaw
Pendant npm install, le postinstall a essayé de patcher OpenClaw, puis a échoué proprement car OpenClaw n’était pas installé. L’installation a continué.
Ce n’est pas grave, mais ça surprend dans un test standalone.
Est-ce que ça marche vraiment ?
Oui, sur ce test, ça marche.
Pas juste au sens « ça démarre ». Le produit a:
- capturé 12 messages,
- écrit le L0,
- extrait 7 souvenirs L1,
- retrouvé des souvenirs via recherche FTS,
- généré un bloc de scène,
- généré un
persona.md, - stocké le tout localement.
La qualité des souvenirs était correcte. Les informations importantes ont été capturées: ton éditorial, stack technique, posture DevOps déterministe, critère d’inspection locale, contexte Jarvis.
Je ne tirerais pas encore de conclusion sur les chiffres de performance du README. Je n’ai pas rejoué leurs benchmarks. Mon test valide surtout l’utilité fonctionnelle sur un petit cas concret.
Pour qui c’est utile
À essayer si vous construisez un agent long terme
Si vous développez un assistant qui doit retenir des préférences, des contraintes projet, des décisions, des scènes de travail, c’est intéressant.
Surtout si vous voulez garder la mémoire locale et inspectable.
Pertinent pour équipes agents, infra, outils internes
Je le vois bien pour:
- assistants internes DevOps,
- agents de support technique,
- copilotes de recherche,
- pipelines de knowledge management,
- environnements où la traçabilité compte.
Moins adapté si vous voulez un SDK minimaliste
Si vous cherchez une librairie très simple à appeler en trois fonctions, ce n’est pas encore ça. Le projet ressemble plus à un plugin système pour agents qu’à une petite dépendance applicative.
Verdict
Essayer.
Je ne dirais pas encore « adopter partout », car l’ergonomie hors OpenClaw reste rugueuse et le cycle L2/L3 mérite une fin de job plus nette.
Mais le coeur fonctionne, et il produit quelque chose de concret: des souvenirs structurés, des scènes, une persona, le tout en local et inspectable.
Pour un agent sérieux, cette approche en couches est plus saine qu’un gros sac de chunks vectoriels. C’est exactement le genre de brique que je garde dans ma short list quand je dois donner de la mémoire à un assistant autonome sans perdre la main sur les données.